一、Kubernetes故障排查先看什么
排查时建议先从现象入手,不要一开始就猜原因。常见入口包括:
- Pod 状态
- 事件信息
- 容器日志
- Service 和 Endpoints
- Node 状态
- 资源配额和限制
- 网络与存储状态
一般顺序是:先看状态,再看事件,再看日志,最后回到调度、网络、存储和权限层面。
二、Pod一直Pending怎么排查
Pod 处于 Pending,通常说明还没有成功调度或依赖资源没有就绪。
常见原因包括:
- 节点资源不足
- nodeSelector 或亲和性不满足
- 污点和容忍度不匹配
- PVC 未绑定
- Namespace 资源配额不足
这类问题优先查看 Pod 事件,通常会看到调度器给出的失败原因。
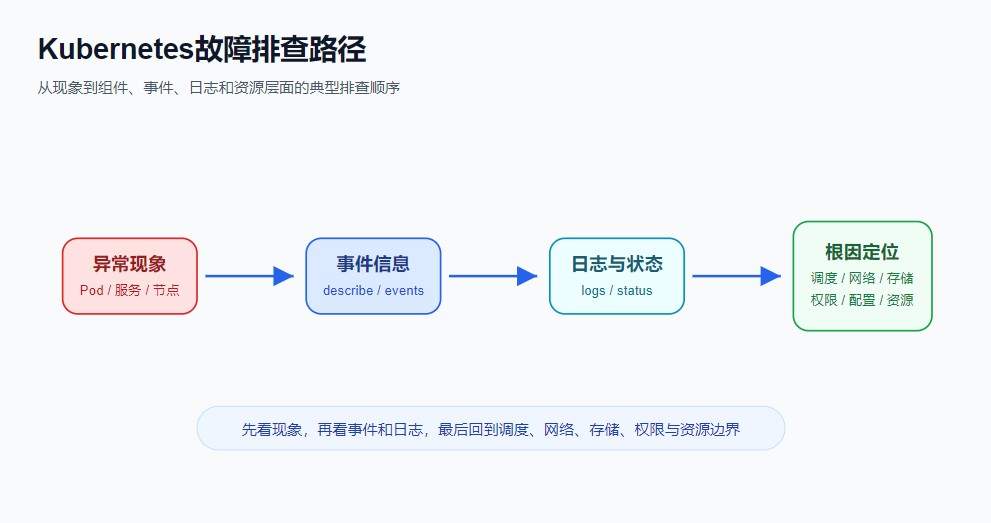

图1:Kubernetes故障排查路径
三、Pod出现ImagePullBackOff怎么办
ImagePullBackOff 通常和镜像拉取有关。常见原因包括:
- 镜像地址写错
- 镜像版本不存在
- 私有仓库凭证缺失
- 节点无法访问镜像仓库
- 镜像仓库限流或不可用
排查时要确认镜像名称、tag、仓库访问和 imagePullSecret 配置。
四、Pod频繁重启怎么排查
Pod 频繁重启常见于 CrashLoopBackOff。原因可能是:
- 应用启动失败
- 配置文件或环境变量错误
- 依赖服务不可用
- 健康检查配置不合理
- 内存超限导致 OOMKill
排查时要结合上一次容器日志、事件、资源使用情况和探针配置一起看。
五、Service访问不通怎么排查
Service 访问不通时,不要只看 Service 是否存在,还要看它是否正确关联后端 Pod。
建议检查:
- Service selector 是否和 Pod 标签匹配
- Endpoints 是否存在
- Pod 是否 Ready
- 端口和 targetPort 是否正确
- NetworkPolicy 是否限制访问
- DNS 解析是否正常
很多 Service 问题其实是 selector 或端口配置错误导致的。
图2:Kubernetes工作负载生命周期
六、Ingress访问异常怎么排查
Ingress 异常通常涉及更多层:
- 域名是否解析到正确入口
- Ingress Controller 是否运行正常
- Ingress 规则是否匹配
- 后端 Service 是否可访问
- TLS 证书是否配置正确
- Controller 日志是否有报错
外部访问链路较长,建议按“域名 → Ingress → Service → Pod”的顺序排查。
七、节点异常怎么排查
Node 异常可能影响大量 Pod。常见问题包括:
- Node NotReady
- 磁盘压力
- 内存压力
- kubelet 异常
- 容器运行时异常
- 网络插件异常
这类问题要结合节点事件、系统资源、kubelet 状态和运行时日志进行分析。
八、排查时要避免什么误区
常见误区包括:
- 只看 Pod,不看事件和日志
- 只看应用,不看调度和资源
- 只看 Service,不看 Endpoints
- 忽略 Namespace 配额和权限
- 网络问题只看 Ingress,不看后端链路
Kubernetes 排障更像链路分析,要逐层缩小范围。
结语
Kubernetes故障排查的关键,是建立从现象到根因的分层路径。Pod 异常、调度失败、服务不可用、网络问题和存储问题,往往不是孤立事件,而是多个资源对象协同失败的结果。按照状态、事件、日志、资源、网络、存储和权限逐层排查,能显著提升定位效率。
FAQ
Kubernetes故障排查先看日志还是事件?
建议先看状态和事件,再看日志。事件通常能说明调度、镜像、存储等平台层原因。
Service存在但访问不通怎么办?
重点检查 selector、Endpoints、Pod Ready 状态、端口配置和网络策略。
CrashLoopBackOff一定是应用代码问题吗?
不一定。配置错误、依赖不可用、探针错误和资源超限都可能导致频繁重启。


