-
 K8s集群搭建步骤:从环境准备到上线验证的完整清单
K8s集群搭建步骤:从环境准备到上线验证的完整清单
-
云原生架构实施路线图:规划步骤与落地路径
云原生技术社区:Kubernetes、容器、DevOps与AI基础设施实践
云原生技术社区聚合 Kubernetes、容器、DevOps、微服务、平台工程、云原生安全和 AI 基础设施等实践内容,帮助开发者、运维团队和平台团队系统理解云原生架构、落地路径和生产环境治理方法。
文章精选
-
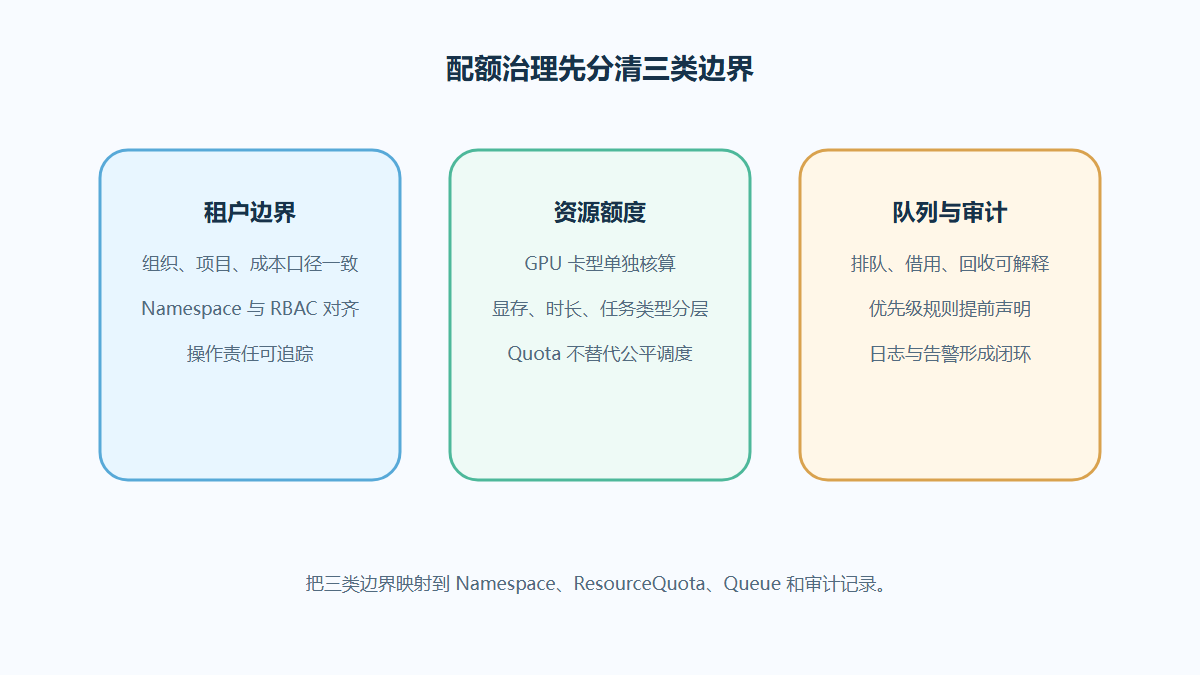
AI平台多租户配额怎么设计?设计租户和队列边界
当多个团队共用同一批 GPU 和模型环境时,AI平台多租户配额的难点常常不是资源本身,而是租户、队列、权限和借用规则没有说清。读完可获得一套可落地的治理检查路径。
-
容器部署和虚拟机部署的区别-5个判断维度
容器部署和虚拟机部署的区别,不只是启动速度和资源开销。本篇用5个判断维度拆解隔离层、交付链路和治理边界,说明哪些场景可先试点容器、哪些场景应继续保持虚拟机,并形成更稳妥的部署组合。
-
容器部署和传统部署哪个好?选型判断框架
容器部署和传统部署哪个好,取决于应用形态、发布频率和运维成熟度。本篇用条件化结论、对比表和迁移路径,帮助你判断哪些应用适合先容器化、哪些仍可继续传统部署,并规划渐进改造顺序。
-
容器部署方式的优点与企业交付收益
想判断容器部署方式的优点,不能只看启动速度。本篇从交付一致性、弹性扩展、环境隔离和运维自动化切入,帮你区分可直接获得的收益、需要平台流程支撑的收益,以及落地前应避开的误区。



最新发布
-
私有镜像仓库证书链怎么治理?检查K8s节点信任
私有镜像仓库证书链出问题时,真正难点往往在K8s节点是否一致信任。这里用节点、containerd和仓库地址三层视角梳理核对顺序,并给出灰度验证与轮换清单,便于在发布前发现证书链隐患。
-
K8s工作流编排:Argo任务治理
当批任务、发布任务和数据处理任务越来越多时,K8s工作流编排容易变成脚本堆叠。这里用Argo治理视角梳理DAG、权限、观测和失败恢复,帮助平台团队判断哪些任务值得模板化,哪些任务只需要普通Job或CI流水线。
-
K8s准入控制可观测性从拒绝率到审计复盘
准入规则上线后,真正需要持续观察的是谁被拒绝、拒绝是否合理、Webhook是否变慢以及审计日志能否支撑回滚。本篇用指标、告警和审计字段梳理K8s准入控制可观测性,帮助团队把策略影响看清楚。
-
K8sRBAC最小权限-4类授权检查
当集群权限越用越乱,K8sRBAC最小权限问题常藏在跨命名空间绑定、默认ServiceAccount和通配符动词里。本篇用检查清单梳理核对路径,帮助你判断哪些授权需要收敛、哪些变更应先验证。
-
K8s优雅终止配置:preStop与SIGTERM策略
滚动更新或缩容时偶发502、连接被重置,往往不是副本数不够,而是终止阶段没有给应用和入口层留出退出窗口。本篇从preStop、SIGTERM和宽限期入手,给出可核对的配置与验证路径。
-
AI工作流编排怎么做?DAG与审批门设计
当AI应用从单次调用走向多步骤Agent任务时,流程失控、审批缺位和失败重跑会迅速放大风险。本篇从DAG节点拆分、人工审批位置、幂等重试、补偿回滚和平台治理清单切入,帮助读者判断哪些流程适合自动化,哪些动作必须保留人工门禁。
-
K8s容器运行时迁移灰度、CRI socket与回滚清单
准备调整节点运行时基线时,风险常藏在socket路径、日志采集、镜像缓存和自动化脚本里。本篇以K8s容器运行时迁移为主线,拆解灰度顺序、关键检查点、监控观察口径和可执行回滚判断,帮助平台团队降低变更影响面。
-
K8s容器隔离原理:Namespace、cgroup与沙箱边界
K8s容器隔离原理经常被误解为“像虚拟机一样安全”。读完本篇内容,你可以分清Namespace、cgroup、capabilities和沙箱运行时各自负责的边界,并知道在多租户场景下该如何评估风险。
-
K8s中GPU共享怎么选?MIG与时间片选择框架
一张GPU卡到底该切成固定实例,还是让多个任务轮流使用?围绕K8s GPU共享,本篇从隔离、显存、性能抖动和租户体验拆解MIG与时间片的取舍,并给出上线前检查清单。
-
GPU资源碎片化治理:画像、配额与调度策略
GPU利用率看似不低,任务却仍在队列里等待,往往不是单点扩容能解决的问题。本篇从GPU资源碎片化治理出发,拆解画像、配额、队列和调度策略如何协同,让剩余算力更容易被真正使用。
-
PVC扩容失败怎么办?检查容器存储、StorageClass与CSI
改了PVC容量却迟迟不生效时,先别急着删卷或重启业务。本篇按事件、StorageClass、CSI、PV/PVC、节点文件系统和应用视角拆解PVC扩容失败,帮助你判断请求卡在哪一段,以及下一步该低风险处理什么。
-
K8s调度插件原理:Filter、Score到Bind
Pod Pending不一定是CPU或内存不够,很多问题藏在调度插件的过滤、打分、预留和绑定阶段。本篇用Filter、Score到Bind的链路解释kube-scheduler如何做决策,并给出排查事件、日志和配置的对应视角。
-
K8s网络策略灰度上线与Pod访问控制回滚清单
准备把NetworkPolicy从测试环境推到生产时,最怕默认拒绝把正常调用、DNS解析或健康检查一起拦掉。本篇按依赖盘点、标签校验、灰度批次、观测指标和回滚条件拆解K8s网络策略上线清单,便于平台与业务团队共同验收。
-
vLLM Kubernetes部署怎么做?配置GPU推理服务
想把 vLLM 从单机示例放到 Kubernetes 上运行,难点通常不在启动命令,而在 GPU、模型文件、服务访问和运行状态验证。这篇文章按部署链路拆解可参考的配置思路。
-
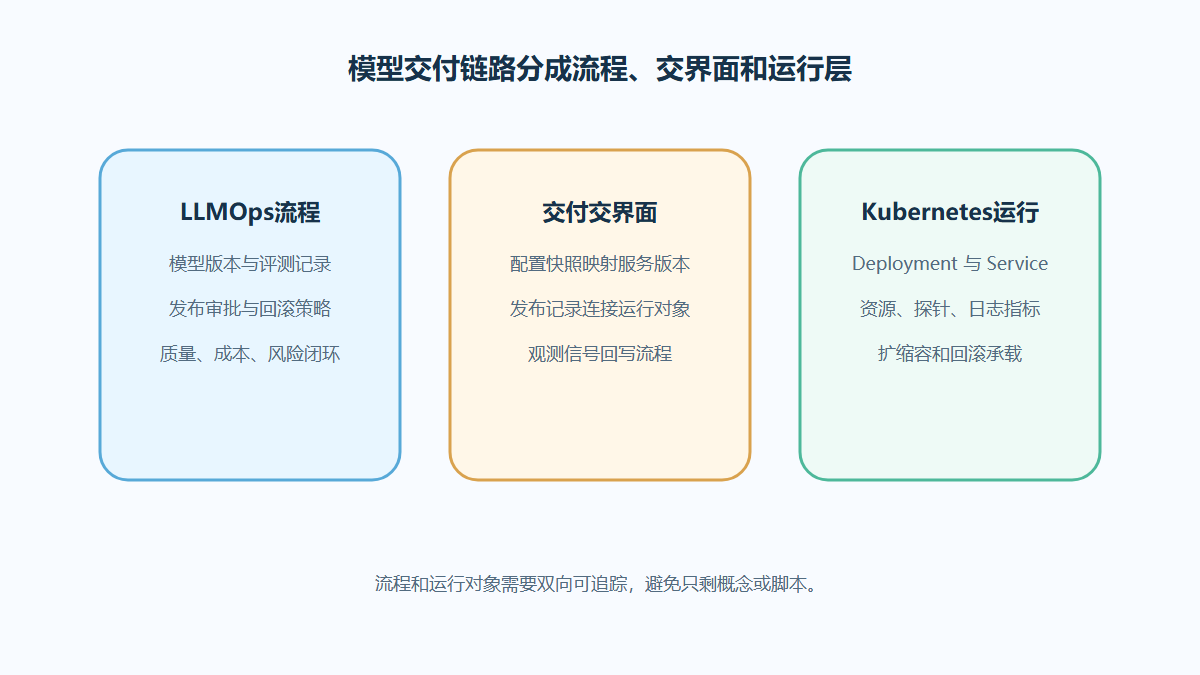
LLMOps Kubernetes模型交付链路设计
大模型上线不是把容器部署到集群就结束。围绕 LLMOps和Kubernetes 的分工,本文梳理模型从注册、发布、扩缩容到观测回滚的交付链路,让平台团队看清先补哪一段能力。
-
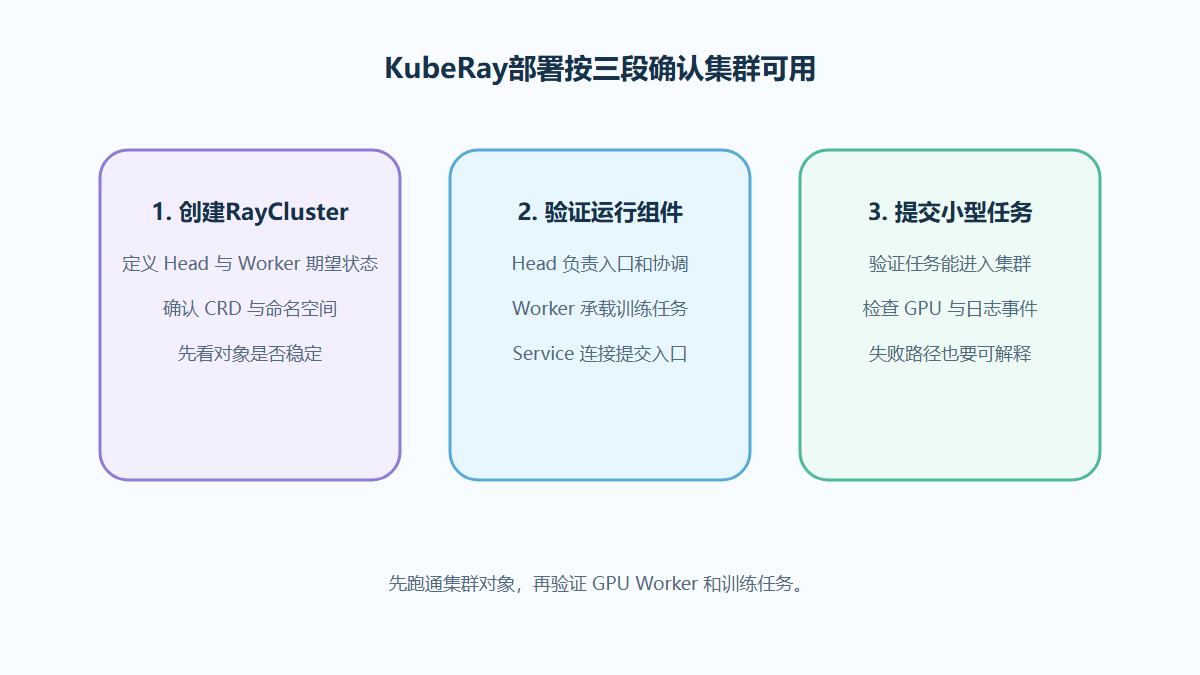
KubeRay部署Ray集群的GPU调度步骤
想用 KubeRay 在 Kubernetes 上跑 Ray 集群,不能只看 RayCluster 是否创建成功。本文从 Head/Worker、GPU申请、训练任务提交和状态验证入手,梳理平台团队可落地的部署步骤。
-
KServe vLLM区别怎么判断?服务层对比方法
纠结 KServe 和 vLLM 怎么选时,先别急着做二选一。一个更偏模型服务层,一个更偏推理执行层;读完本文可以用层级、职责和场景矩阵判断它们在平台中的位置。
-
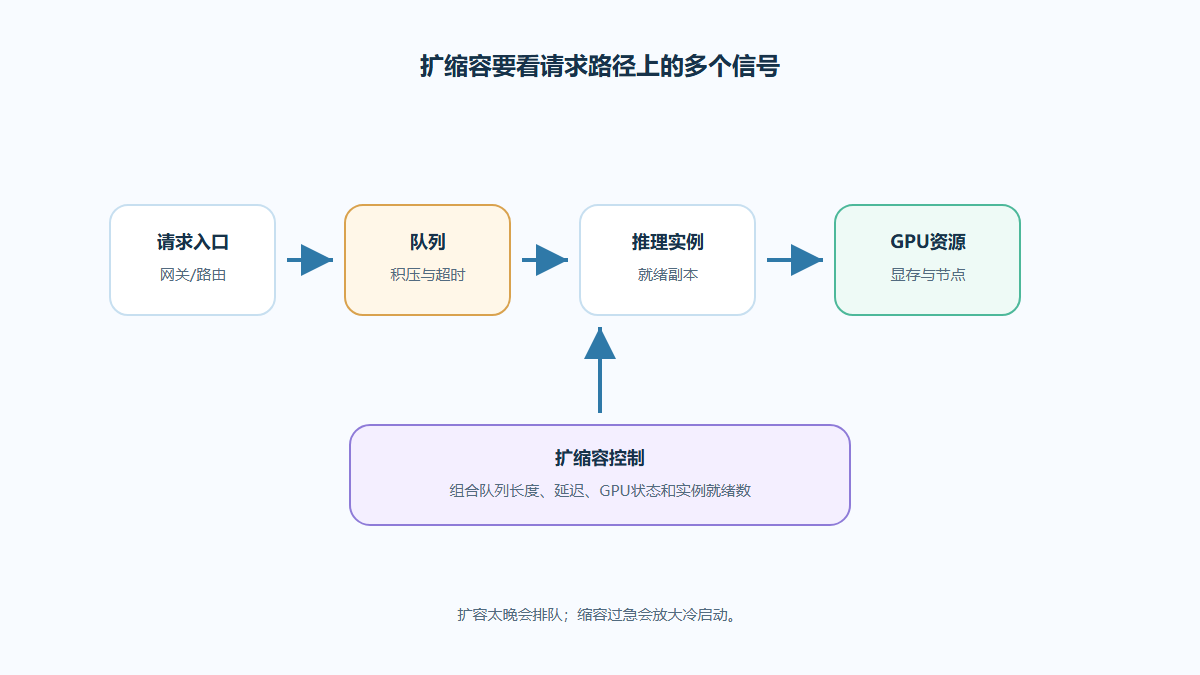
K8s模型推理扩缩容:HPA、队列、冷启动
推理服务明明开了 HPA,却还是排队、冷启动或 GPU 利用率异常?这篇内容把 CPU、队列、显存和模型加载放在同一条链路里看,给出 K8s模型推理扩缩容的判断框架和落地边界。
-
K8s GPU Operator部署-3步验证节点
集群已经有 GPU 节点,却不知道 Operator 是否真正生效?这篇内容从驱动、Device Plugin、节点标签和 Pod 调度结果入手,给出可复用的 K8s GPU Operator 验证路径。
-
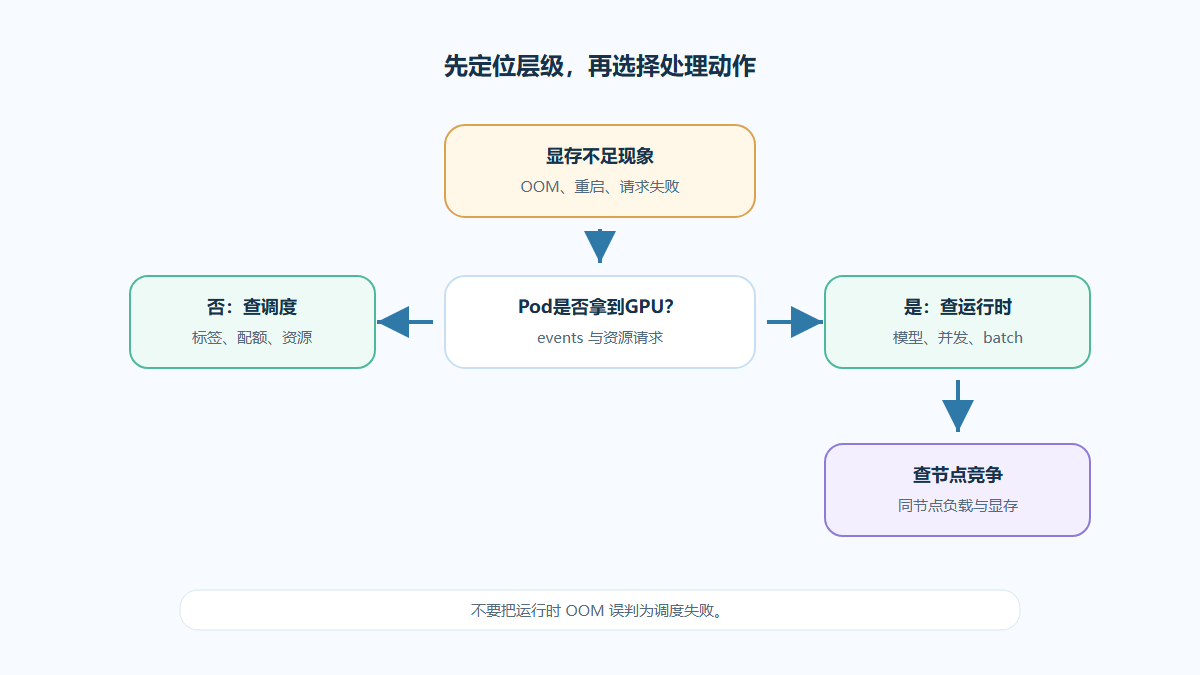
GPU显存不足怎么排查?定位Pod与模型配置
遇到 CUDA out of memory、Pod 重启或推理请求失败时,先别急着加卡或降级模型。本文用 K8s 视角串起事件、日志、资源请求、batch size 和显存预算,帮助定位真正瓶颈。