AI基础设施
如果你正在规划企业级 AI 平台,可以从算力资源、模型训练与推理、MLOps、智能体开发和平台治理几个方向进入。AI 基础设施不是单点 GPU 采购,而是算力、数据、模型、服务和运维治理的组合能力。
-
AI工作流编排怎么做?DAG与审批门设计
当AI应用从单次调用走向多步骤Agent任务时,流程失控、审批缺位和失败重跑会迅速放大风险。本篇从DAG节点拆分、人工审批位置、幂等重试、补偿回滚和平台治理清单切入,帮助读者判断哪些流程适合自动化,哪些动作必须保留人工门禁。
-
K8s中GPU共享怎么选?MIG与时间片选择框架
一张GPU卡到底该切成固定实例,还是让多个任务轮流使用?围绕K8s GPU共享,本篇从隔离、显存、性能抖动和租户体验拆解MIG与时间片的取舍,并给出上线前检查清单。
-
GPU资源碎片化治理:画像、配额与调度策略
GPU利用率看似不低,任务却仍在队列里等待,往往不是单点扩容能解决的问题。本篇从GPU资源碎片化治理出发,拆解画像、配额、队列和调度策略如何协同,让剩余算力更容易被真正使用。
-
vLLM Kubernetes部署怎么做?配置GPU推理服务
想把 vLLM 从单机示例放到 Kubernetes 上运行,难点通常不在启动命令,而在 GPU、模型文件、服务访问和运行状态验证。这篇文章按部署链路拆解可参考的配置思路。
-
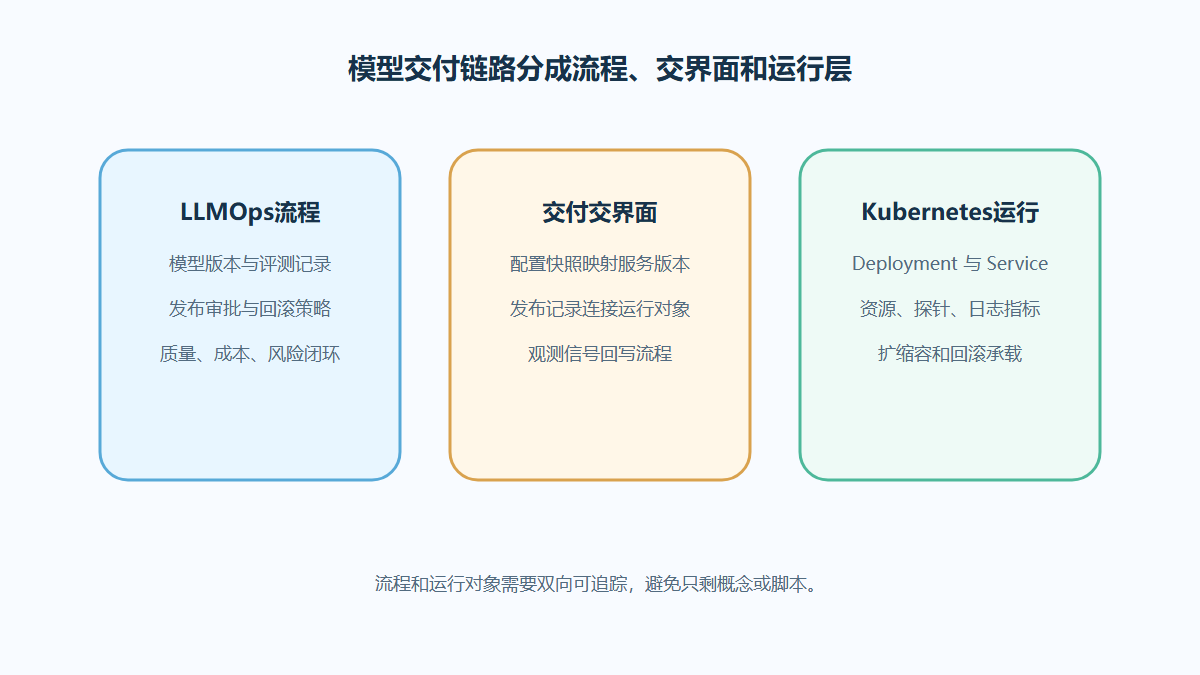
LLMOps Kubernetes模型交付链路设计
大模型上线不是把容器部署到集群就结束。围绕 LLMOps和Kubernetes 的分工,本文梳理模型从注册、发布、扩缩容到观测回滚的交付链路,让平台团队看清先补哪一段能力。
-
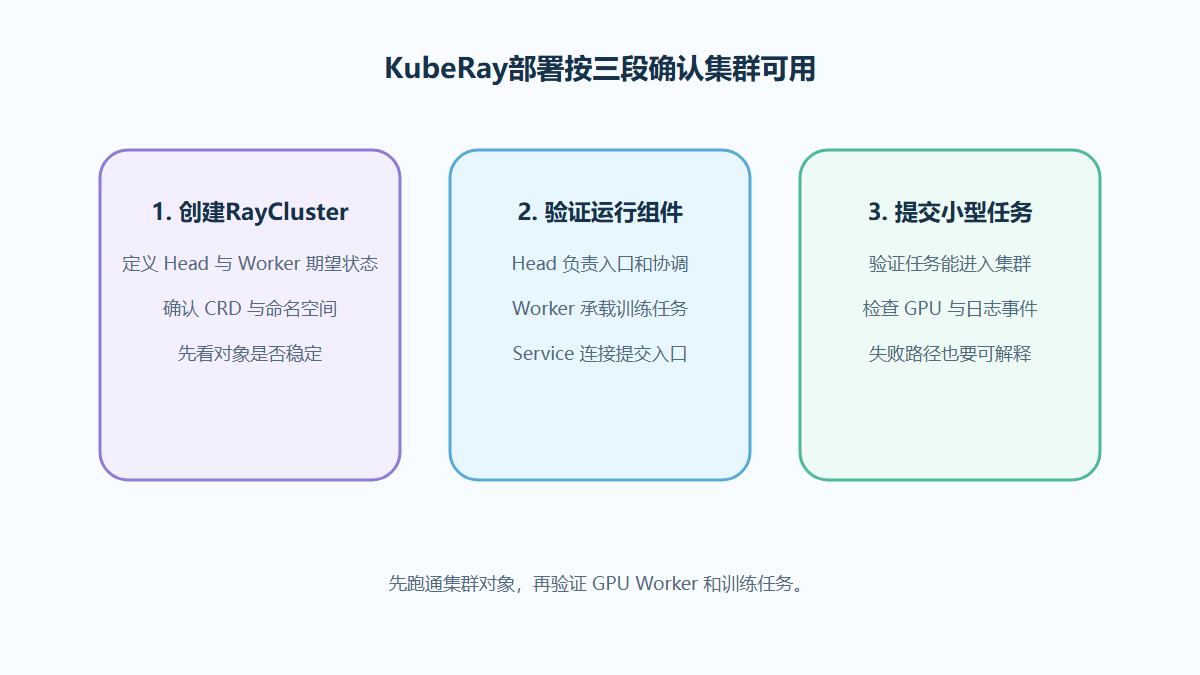
KubeRay部署Ray集群的GPU调度步骤
想用 KubeRay 在 Kubernetes 上跑 Ray 集群,不能只看 RayCluster 是否创建成功。本文从 Head/Worker、GPU申请、训练任务提交和状态验证入手,梳理平台团队可落地的部署步骤。
-
KServe vLLM区别怎么判断?服务层对比方法
纠结 KServe 和 vLLM 怎么选时,先别急着做二选一。一个更偏模型服务层,一个更偏推理执行层;读完本文可以用层级、职责和场景矩阵判断它们在平台中的位置。
-
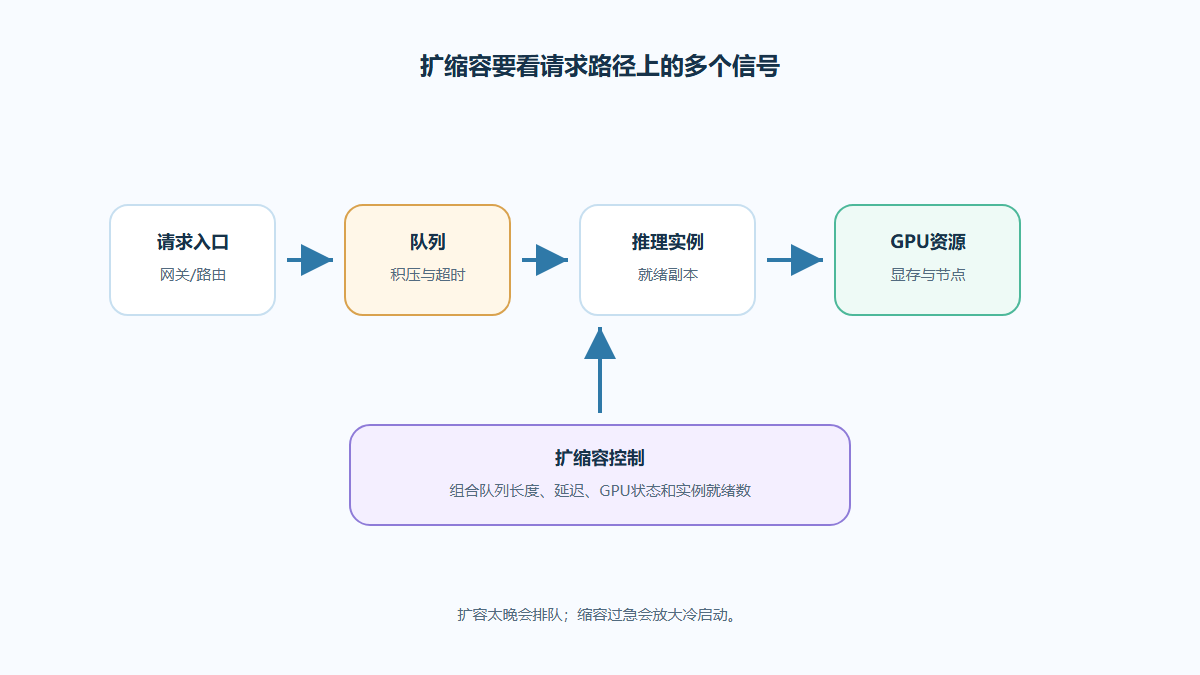
K8s模型推理扩缩容:HPA、队列、冷启动
推理服务明明开了 HPA,却还是排队、冷启动或 GPU 利用率异常?这篇内容把 CPU、队列、显存和模型加载放在同一条链路里看,给出 K8s模型推理扩缩容的判断框架和落地边界。
-
K8s GPU Operator部署-3步验证节点
集群已经有 GPU 节点,却不知道 Operator 是否真正生效?这篇内容从驱动、Device Plugin、节点标签和 Pod 调度结果入手,给出可复用的 K8s GPU Operator 验证路径。
-
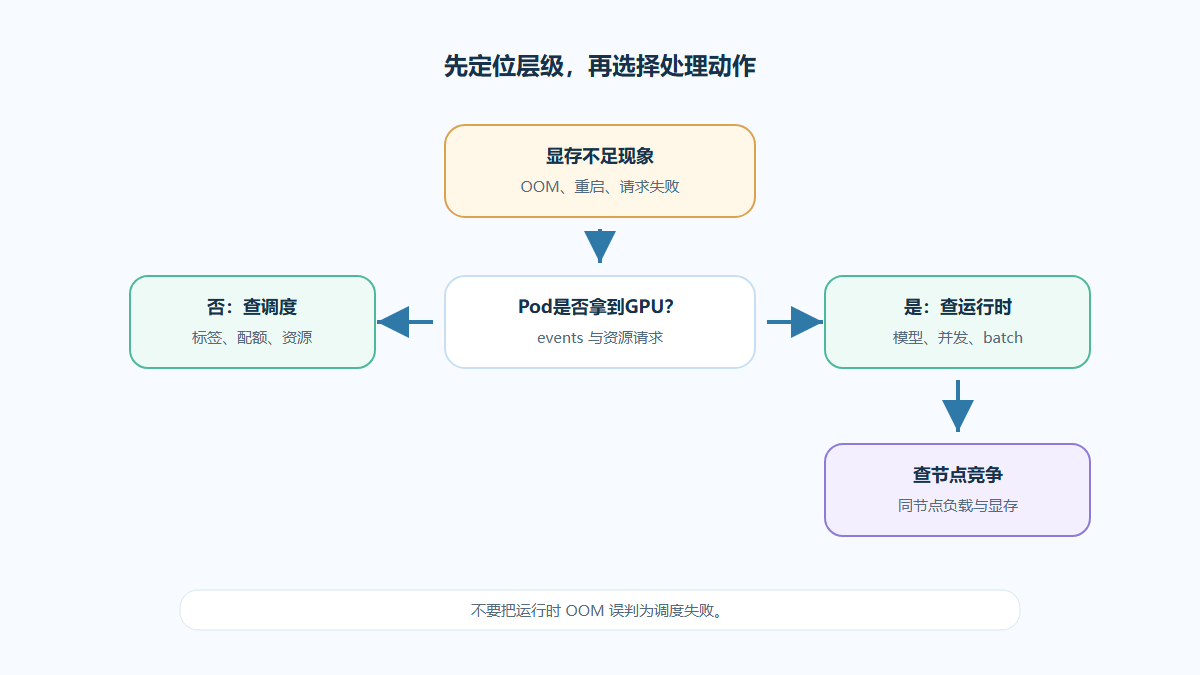
GPU显存不足怎么排查?定位Pod与模型配置
遇到 CUDA out of memory、Pod 重启或推理请求失败时,先别急着加卡或降级模型。本文用 K8s 视角串起事件、日志、资源请求、batch size 和显存预算,帮助定位真正瓶颈。
-
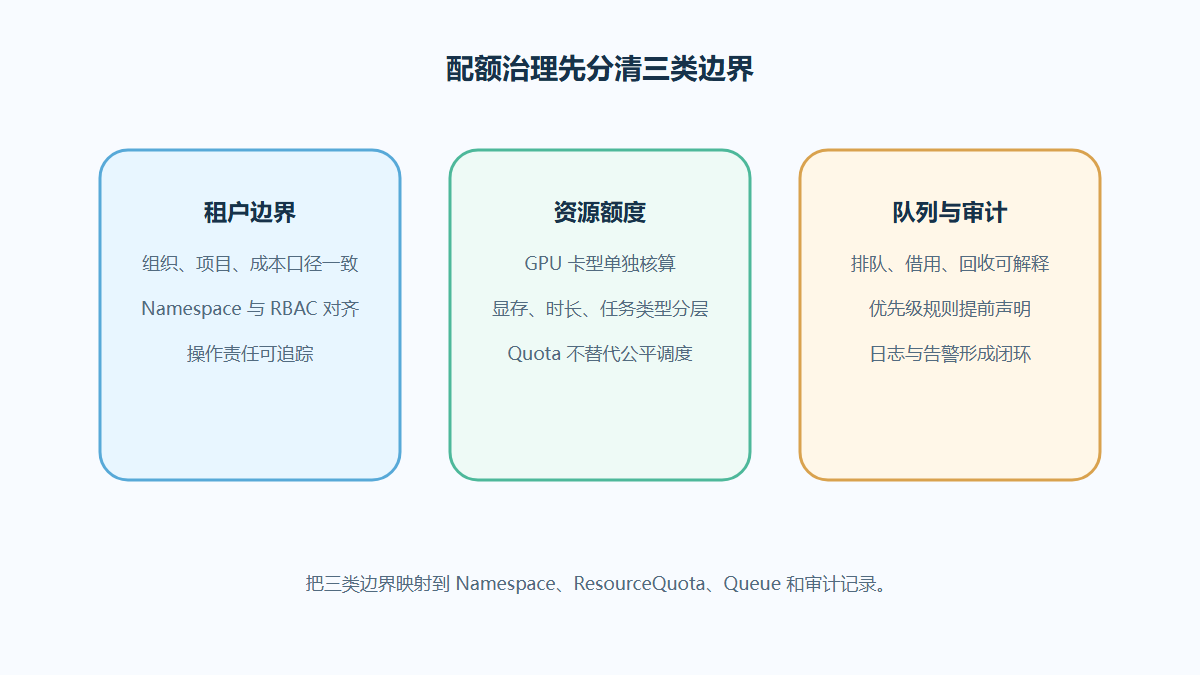
AI平台多租户配额怎么设计?设计租户和队列边界
当多个团队共用同一批 GPU 和模型环境时,AI平台多租户配额的难点常常不是资源本身,而是租户、队列、权限和借用规则没有说清。读完可获得一套可落地的治理检查路径。
-
GPU算力平台采购-5项POC验证点
GPU 资源紧张、团队抢卡和 AI 任务交付压力并存时,采购 POC 不能只跑通一个示例。本文围绕 GPU算力平台采购的 5 项验证点,拆解接入、调度、任务、观测和治理证据。
-
GPU推理副本数设置怎么做?显存判断方法
GPU推理副本数设置容易被 QPS、显存和冷启动同时影响。本篇用单副本显存、并发拐点、GPU调度边界和上线验证流程,帮助团队先定保守初始值,再通过压测和真实流量校准。
-
云原生AI基础设施架构-5层能力清单
AI应用从试点走向生产后,平台团队往往同时面对算力排队、模型追溯、推理发布和治理审计压力。本篇用5层能力清单拆解云原生AI基础设施,帮助你快速定位架构短板和下一步建设重点。
-
企业AI平台建设:权限、算力与模型资产
模型、数据集、GPU 队列和推理服务分散在不同系统时,企业AI平台容易变成“能跑但难管”。本篇从项目权限、算力配额、模型版本和发布审计切入,帮助团队判断平台建设优先级。
-
大模型训练流程怎么走?从数据到发布步骤
从数据集、GPU 资源到模型发布,大模型训练容易卡在版本、权限、评测和产物管理上。本篇按阶段拆解大模型训练流程,帮助你判断哪些步骤适合先平台化,哪些边界需要保留人工确认。
-
GPU管理平台有哪些?灵雀云算力治理
GPU 资源越来越贵,真正难题往往不是“有没有平台”,而是谁能把卡型、队列、配额、租户和训练推理任务管起来。本篇聚焦灵雀云算力治理视角,帮助你评估 GPU管理平台该补哪些企业级能力。
-
AI智能体搭建教程:工具链与上线步骤
第一次搭 AI 智能体时,最容易卡在“先选框架还是先接业务系统”。这篇教程用路线图方式拆开最小原型、工具链取舍、示例工作流和部署门禁,帮助你从可跑 Demo 走向可交付版本。
-
Agent大语言模型是什么?架构与边界
当团队讨论 Agent、大模型和智能体平台时,最容易混淆的是“模型能力”和“任务执行系统”。本文用架构拆解 Agent大语言模型的组成、工作流和限制,帮助你判断哪些场景适合做 Agent,哪些只需要普通 LLM 应用。
-
Agent智能体搭建步骤:从规划到验证
当 Agent 原型准备进入项目评审时,团队需要的不再是工具链总览,而是每一步谁签字、看什么证据、哪些权限不能越过。本文提供 Agent智能体搭建步骤清单,适合启动会、评审会和上线前验收使用。















AI基础设施常见问题
AI基础设施通常包括哪些核心能力?
AI基础设施通常包括算力资源、数据访问、模型训练、模型部署、推理服务、实验管理、监控评估和权限治理。对于企业团队,它不是单独购买 GPU,也不是只搭建一个模型服务,而是要支撑模型从开发、训练、评估到上线运行的完整流程。
规划时可以按三层拆解:底层是 GPU、存储、网络和容器平台;中间层是调度、队列、镜像、数据集和模型仓库;上层是 MLOps、LLMOps、推理服务、智能体应用和可观测性。不同业务阶段关注点不同,不宜一开始就追求全量平台。
企业建设AI基础设施应该先看算力还是先看平台?
如果当前主要瓶颈是训练排队、GPU利用率低或多团队抢资源,应优先梳理算力池化、队列、配额和调度策略。如果瓶颈是模型交付慢、版本不可追踪、部署和回滚困难,则应优先建设 MLOps 或模型服务平台。
更稳妥的方式是先用一个典型业务场景做闭环验证,例如从数据准备、模型训练、模型部署到推理监控跑通,再根据瓶颈决定下一阶段投入。只堆算力而没有调度和平台治理,长期会导致资源浪费和协作混乱。
AI平台和传统云原生平台有什么关系?
AI平台通常建立在云原生平台之上,复用 Kubernetes、容器镜像、存储、网络、监控、权限和 CI/CD 等能力,但会额外引入 GPU 调度、模型仓库、实验追踪、推理服务、Prompt 管理和模型评估等 AI 专属能力。
两者的关系不是替代,而是叠加。云原生平台解决标准运行和资源治理问题,AI平台解决模型生命周期和算力效率问题。企业如果已有容器平台,可以优先在其上扩展 AI 工作负载治理,而不是另起一套孤立平台。
AI基础设施如何避免成为资源孤岛?
资源孤岛通常来自不同团队各自采购 GPU、各自维护训练环境和模型服务,缺少统一配额、镜像、数据、权限和监控。短期看启动快,长期会导致利用率低、重复建设和安全审计困难。
建议从统一资源池、统一镜像规范、统一身份权限和统一监控开始治理,再逐步补齐任务队列、成本归因和多租户隔离。平台不一定一开始很复杂,但关键能力要能让资源被共享、被追踪、被审计。
显示更多
训练、推理和智能体应用对基础设施的要求有什么不同?
训练更关注大规模算力、数据吞吐、任务队列、检查点和实验管理;推理更关注延迟、吞吐、弹性伸缩、灰度发布和稳定性;智能体应用则更关注工具调用、工作流编排、权限边界和执行过程可观测。
因此同一个 AI 平台需要按工作负载类型设计能力,而不是只提供一种运行环境。训练任务可以偏批处理和队列化,推理服务需要更强在线稳定性,智能体应用还要重点处理安全、审计和业务流程集成。
AI基础设施建设如何衡量效果?
可以从 GPU 利用率、训练排队时间、模型部署频率、推理延迟、模型版本可追踪性、故障恢复时间和平台自服务使用率评估。不要只看服务器数量或模型数量,这些指标不能说明平台是否真正提升了效率。
对管理者而言,还要关注成本归因、团队复用率和合规审计。一个有效的 AI 基础设施平台,应该让业务团队更快交付模型,同时让平台团队能控制资源、风险和长期成本。