当平台上只有少量模型时,部署流程通常还能靠人工维护;当模型数量增加后,资源、路由、版本和权限问题会迅速变复杂。
多模型部署的核心挑战,不是把更多模型放到同一套平台上,而是让不同模型之间有清晰边界。没有治理边界的多模型平台,很容易从资源共享变成风险共享。
资源隔离、路由策略、版本关系和观测拆分,是多模型部署治理的四个基础方向。


图1:多模型部署治理
相关主题可以结合 模型部署、模型推理、AI基础设施 一起阅读。本文重点放在推理与部署的工程边界、稳定性指标和平台化治理方法上,避免只停留在概念解释。
资源隔离先定义影响范围
多个模型共享资源时,需要明确哪些模型可以共用 GPU,哪些模型必须独立资源,哪些租户需要隔离。
隔离不是越强越好,过度隔离会降低利用率;隔离不足又会造成延迟抖动和故障扩散。
资源隔离的目标,是让共享收益和风险边界同时可控。
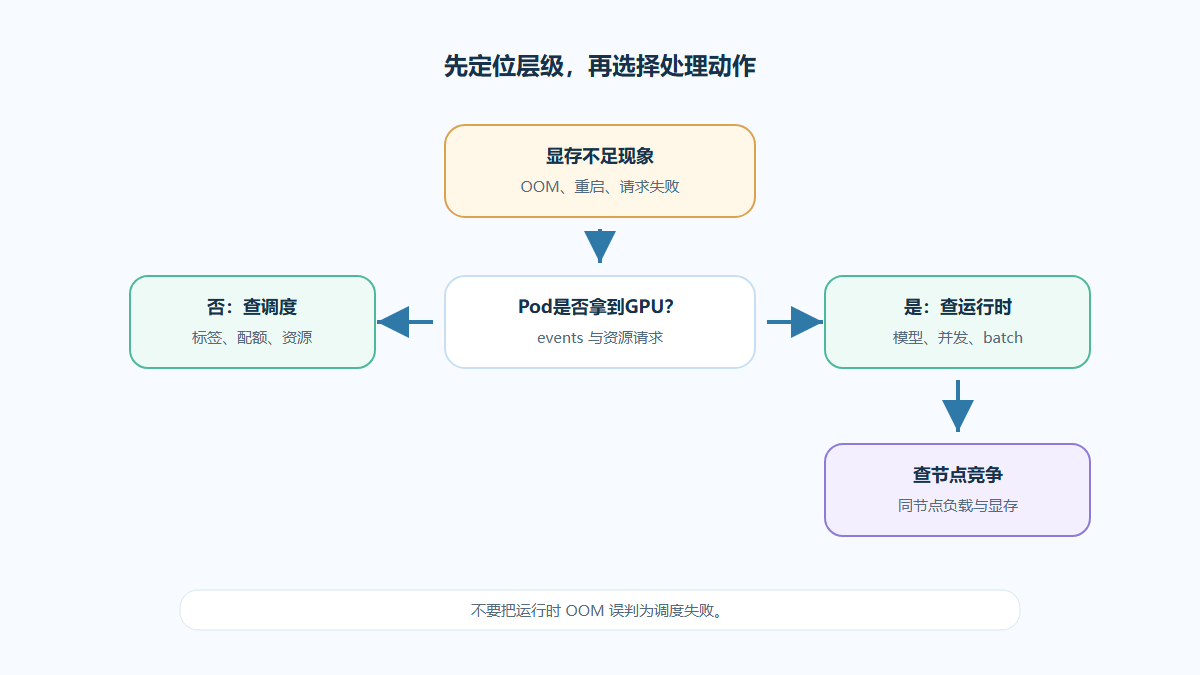
显存和副本是关键边界
多模型部署中,显存通常比算力更早成为瓶颈。一个模型的显存增长,可能导致另一个模型加载失败。
平台需要按模型记录显存需求、上下文长度、批处理策略和副本数量,避免资源估算过粗。
当模型共享节点时,应设置明确的资源上限和驱逐策略。

图2:多模型部署治理判断框架
路由规则要避免交叉污染
多模型平台需要根据模型、版本、租户、场景和灰度策略分发请求。路由规则如果不清晰,请求可能进入错误版本或错误模型。
路由层还要支持快速切流、限流和回滚,避免单个模型异常拖累入口服务。
路由治理决定多模型平台是否能安全承接复杂流量。
版本边界要和服务边界对齐
一个模型可能有多个版本,一个服务也可能组合多个模型。平台需要清楚模型版本、服务版本和业务版本之间的映射。
如果只记录模型文件版本,无法解释线上请求到底经过了哪组模型和配置。
版本边界清楚后,灰度、回滚、审计和问题定位都会更容易。

图3:多模型部署治理落地路径
观测必须按模型拆分
多模型平台不能只看整体延迟和错误率。整体指标正常时,某个低流量模型可能已经出现严重问题。
指标应按模型、版本、租户、入口和资源池拆分,至少能定位慢请求和错误集中在哪里。
没有拆分观测,多模型部署的问题会被平均值掩盖。
治理能力要逐步产品化
多模型部署初期可以先通过规范和脚本维护,但规模上来后,需要平台提供模型注册、资源模板、路由配置、发布审批和审计能力。
平台化不意味着流程变重,而是把高频风险点变成可复用能力。
当团队可以清楚回答某个模型用了哪些资源、接了哪些流量、运行哪个版本,多模型治理才算有基础。
多模型治理先建立目录
当平台上的模型数量增多后,第一步不是优化调度算法,而是建立清晰的模型目录。目录中应记录模型用途、负责人、服务等级、资源需求、版本状态和调用入口。
没有模型目录,平台很难判断哪些模型是核心服务,哪些模型可以下线,哪些模型占用了过多资源。治理多模型,先要知道平台上到底有哪些模型以及它们为什么存在。
模型目录还能帮助团队识别重复模型、僵尸模型和无人维护模型,为后续资源优化提供依据。
资源池要按风险分层
多模型共池能提高资源利用率,但不同模型的风险等级不一样。核心在线模型、灰度模型、实验模型和离线模型不应毫无边界地混在一起。
平台可以按服务等级、资源类型和租户边界划分资源池。关键模型有稳定资源,低频模型使用共享资源,实验模型限制影响范围。
资源池分层的价值,是让共享资源不会变成共享故障。
路由配置需要可审计
多模型平台中,路由规则决定请求进入哪个模型、哪个版本和哪个副本。任何一次灰度、切流或回滚都应该有记录。
如果路由配置缺少审计,出现问题时团队很难知道请求为什么进入某个版本,也无法判断异常影响了哪些租户。
路由审计不只是合规需求,更是故障排查和发布复盘的基础能力。
生命周期管理避免平台膨胀
模型上线后如果缺少下线机制,平台会持续积累低频、过期或无人维护的模型。这些模型占用资源、增加路由复杂度,也会拖慢平台治理。
生命周期管理应包括候选、灰度、线上、低频、废弃和归档状态,并定期复查模型使用情况。
多模型治理的长期目标,不是无限承载更多模型,而是让有价值的模型稳定运行,让无价值的模型及时退出。
多模型治理的落地顺序
第一阶段先建立模型目录和负责人,解决“有哪些模型、谁负责、是否仍在使用”的问题。第二阶段再做资源和路由治理,明确哪些模型共享资源、哪些模型独立部署、哪些模型可以灰度。
第三阶段补观测和生命周期管理,按模型和版本拆分指标,并定期清理低频、过期或无人维护的模型。这个顺序比一开始就做复杂调度更稳。
多模型治理不是一次性项目,而是随着模型规模增长逐步补齐边界。每增加一类模型,就要评估它是否需要新的资源池、路由规则或观测维度。
治理指标如何设计
多模型治理需要一组能反映平台健康度的指标。除了常见的延迟、错误率和资源使用,还应关注模型数量、活跃模型比例、无人维护模型数量、版本数量、灰度中的模型数量和资源池利用率。
这些指标能帮助平台团队判断治理是否失控。例如模型数量持续增加但活跃调用很少,说明存在沉淀清理问题;版本数量过多且缺少状态,说明版本治理需要加强。
治理指标不一定直接面向业务用户,但对平台长期健康很重要。它能让团队在问题变成事故前,发现复杂度正在累积。
小结
多模型部署越往后,越考验平台的边界管理能力。模型目录、资源池分层、路由审计、版本关系和生命周期管理做清楚后,多模型平台才能既保持资源效率,又避免单个模型的问题扩散到整个平台。
常见问题
多模型部署最容易在哪些地方失控?
最常见的是模型目录混乱、资源池没有分层、路由规则缺少审计、版本关系不清楚,以及低优先级模型占用关键资源。随着模型数量增加,如果每个团队都按自己的方式上线,平台很快会出现命名冲突、显存争抢、灰度不可控和回滚困难。多模型治理的重点不是限制模型数量,而是建立清晰的资源、版本和路由边界。
多模型是否应该共用同一个资源池?
可以共用底座,但不应没有边界。核心在线模型、批量推理、实验模型和低频内部模型对延迟、稳定性和成本的要求不同,应通过队列、配额、优先级、节点池或命名空间做隔离。否则一个批量任务或实验模型的显存占用,就可能影响关键在线服务,问题发生时也很难快速定位责任范围。
路由治理为什么是多模型平台的核心问题?
多模型场景下,请求不仅要找到某个服务,还要命中正确的模型版本、灰度策略、租户边界和资源状态。路由规则如果缺少审计和版本记录,线上问题会很难回溯,例如不知道某个租户何时切到了新版本、某个入口是否绕过了灰度、某个副本为什么仍在接流量。路由治理应和模型目录、发布记录、健康状态联动。
多模型平台什么时候需要生命周期管理?
当模型数量开始持续增长、历史版本长期存在、实验模型没人清理、资源占用越来越不透明时,就需要生命周期管理。生命周期管理包括模型准入、上线、灰度、下线、归档和删除策略。它不是单纯做清理,而是让团队知道哪些模型仍在服务、谁负责、占用多少资源、是否还能回滚,以及何时可以安全下线。