AI算力调度
如果你正在处理 GPU 资源紧张、训练排队、资源利用率低或多团队共享问题,可以从资源池化、队列、配额、优先级和成本归因几个方向进入。这个分类更关注 AI 算力如何被高效、安全、可治理地使用。
-
K8s中GPU共享怎么选?MIG与时间片选择框架
一张GPU卡到底该切成固定实例,还是让多个任务轮流使用?围绕K8s GPU共享,本篇从隔离、显存、性能抖动和租户体验拆解MIG与时间片的取舍,并给出上线前检查清单。
-
GPU资源碎片化治理:画像、配额与调度策略
GPU利用率看似不低,任务却仍在队列里等待,往往不是单点扩容能解决的问题。本篇从GPU资源碎片化治理出发,拆解画像、配额、队列和调度策略如何协同,让剩余算力更容易被真正使用。
-
K8s GPU Operator部署-3步验证节点
集群已经有 GPU 节点,却不知道 Operator 是否真正生效?这篇内容从驱动、Device Plugin、节点标签和 Pod 调度结果入手,给出可复用的 K8s GPU Operator 验证路径。
-
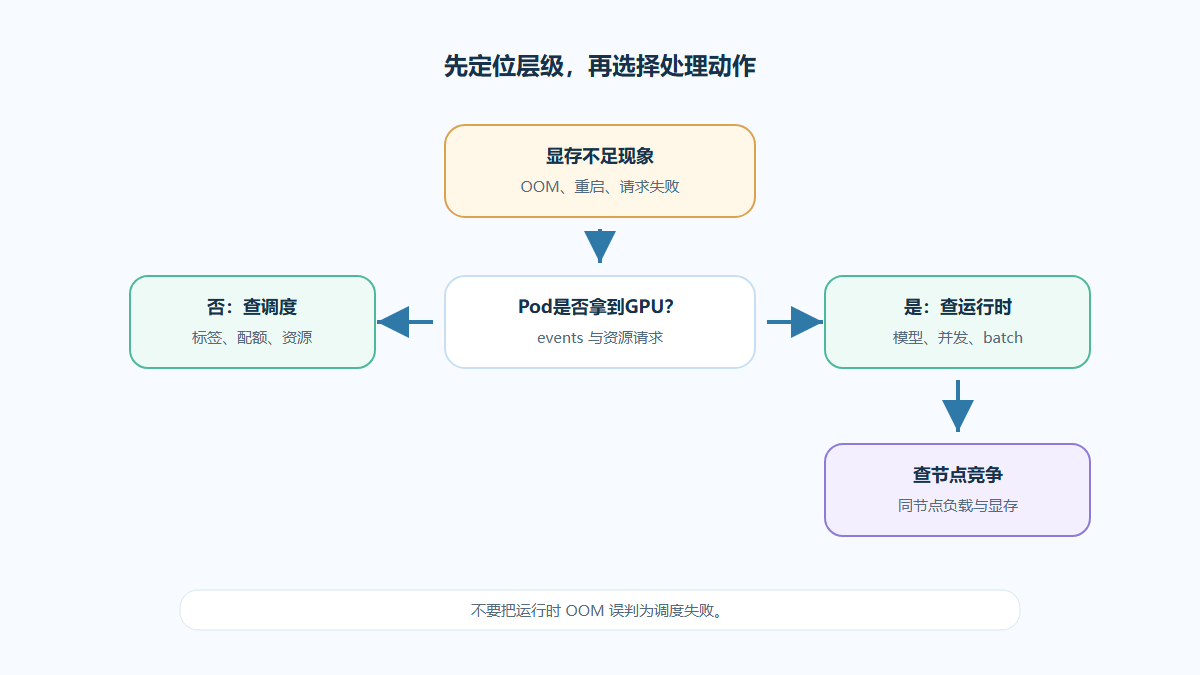
GPU显存不足怎么排查?定位Pod与模型配置
遇到 CUDA out of memory、Pod 重启或推理请求失败时,先别急着加卡或降级模型。本文用 K8s 视角串起事件、日志、资源请求、batch size 和显存预算,帮助定位真正瓶颈。
-
GPU算力平台采购-5项POC验证点
GPU 资源紧张、团队抢卡和 AI 任务交付压力并存时,采购 POC 不能只跑通一个示例。本文围绕 GPU算力平台采购的 5 项验证点,拆解接入、调度、任务、观测和治理证据。
-
GPU管理平台有哪些?灵雀云算力治理
GPU 资源越来越贵,真正难题往往不是“有没有平台”,而是谁能把卡型、队列、配额、租户和训练推理任务管起来。本篇聚焦灵雀云算力治理视角,帮助你评估 GPU管理平台该补哪些企业级能力。
-
万卡集群算力评审清单-资源池网络与调度联审
万卡集群算力评审不应只汇报 GPU 数量和预算。本文把规划材料拆成资源池、网络、存储、调度和验收证据,帮助多团队在扩容前对失败信号、责任边界和复盘口径达成一致。
-
大模型平台有哪些类型?生命周期能力地图与建设顺序
大模型平台建设常卡在“先买一套平台还是复用现有系统”。本文按模型生命周期梳理底座能力、上层治理和复用边界,帮助团队判断当前阶段先补训练、推理、注册还是 LLMOps。
-
GPU集群管理软件选型矩阵-5类方案与PoC清单
GPU集群管理软件选型不能只看控制台功能。本文把五类方案放到同一张矩阵中,帮助团队按任务规模、既有技术栈、集成成本和受控失败 PoC 判断哪类方案更适合当前阶段。
-
算力调度模型评审清单:队列配额如何落地
队列、配额和优先级真正上线后,争议通常来自策略解释、变更留痕和回滚条件。本文把算力调度模型拆成评审清单,帮助平台团队在上线前确认规则能被执行、审计和复盘。
-
向量检索服务怎么部署?索引、存储与可观测性
向量检索服务上线后,问题往往出在索引更新、召回延迟、存储增长和权限边界上。把索引、数据、服务和观测一起设计,才能支撑稳定的 RAG 与语义检索应用。
-
模型注册中心怎么建设?元数据、权限与生命周期
模型文件越来越多时,团队最先遇到的问题不是存储空间,而是谁能使用、哪个版本可信、能否发布、出了问题能否追溯。模型注册中心把这些信息组织成可管理的生命周期。
-
模型评测流水线怎么搭建?离线指标与线上反馈
模型能不能上线,不能只看一次离线分数。评测流水线需要把样本、指标、版本、业务反馈和发布决策连接起来,让每次模型变化都有可比较、可追溯的依据。
-
LLMOps平台要具备哪些能力?提示词、评测与发布治理
大模型应用上线后,变化的不只是模型文件,提示词、工具调用、知识库、评测集和路由策略都会影响结果。LLMOps 平台要把这些变化纳入可测试、可发布、可回滚的流程。
-
GPU资源池怎么规划?节点分层、配额与隔离策略
GPU 资源池不是把所有显卡放进同一个集群就结束。不同型号、显存、网络、任务类型和业务等级会产生不同约束,规划不好会导致高端卡浪费、低优先级任务挤占核心服务。
-
GPU集群观测看什么?利用率、显存与容量风险
GPU 利用率高不一定代表资源健康,显存接近上限、排队时间变长、节点故障或资源碎片都会影响 AI 任务交付。GPU 集群观测要把资源、任务和容量风险放在一起看。
-
AI工作负载调度怎么做?训练、推理与优先级队列
AI 平台里既有长时间训练,也有低延迟推理,还有临时实验和批量生成任务。它们对 GPU、显存、网络、等待时间和稳定性的要求不同,调度策略必须分层设计。
-
AI平台多租户怎么做?资源隔离、权限与成本归因
当多个团队共用同一套 AI 平台时,最容易出现资源争抢、权限过宽、成本不清和故障影响扩散。多租户治理要让共享资源既能复用,又不会失去边界。
-
AI推理网关怎么设计?路由、鉴权与配额治理
当模型数量和调用方增加后,直接暴露推理服务会让鉴权、路由、限流和观测分散在各处。AI 推理网关把调用入口统一起来,让多模型服务具备更清晰的治理边界。
-
AI数据管道怎么设计?特征、样本与训练推理一致性
很多模型问题不是算法本身造成,而是训练和推理看到的数据不一致。AI 数据管道要把样本、特征、质量校验和血缘关系串起来,让模型效果有稳定数据基础。



















AI算力调度常见问题
AI算力调度主要解决哪些问题?
AI算力调度主要解决 GPU 等稀缺资源如何分配、排队、隔离和回收的问题。随着训练任务、推理服务和多团队需求增加,如果没有统一调度,常见问题包括资源长期占用、利用率低、任务排队不透明和成本难以归因。
有效的调度体系通常包括资源池化、队列、配额、优先级、抢占、任务画像和监控统计。它的目标不是简单把任务跑起来,而是让不同团队在统一规则下公平、高效地使用算力。
GPU利用率低一定是资源不够吗?
不一定。GPU 利用率低可能来自任务调度不合理、数据加载瓶颈、资源申请过大、训练代码效率低或长时间占用但实际空闲。直接增加 GPU 数量可能会掩盖问题,反而扩大成本。
排查时建议同时看 GPU 使用率、显存、任务等待时间、数据吞吐和用户队列行为。只有确认瓶颈确实来自资源供给不足,再考虑扩容;否则应优先优化调度和任务配置。
多租户算力平台要重点关注什么?
多租户场景要重点关注身份权限、资源配额、队列隔离、数据访问边界和成本归因。不同团队共享同一算力池时,如果没有配额和优先级,很容易出现少数任务长期占用资源,影响整体效率。
平台还需要提供透明的排队和使用记录,让业务团队知道任务为什么等待、用了多少资源、成本归属到哪里。否则算力平台会变成黑盒,平台团队也难以做容量规划。
AI算力调度和Kubernetes调度有什么关系?
Kubernetes 提供通用容器调度能力,但 AI 工作负载对 GPU、显存、队列、分布式训练和任务优先级有更强要求。企业通常需要在 Kubernetes 之上扩展 GPU 调度、批任务队列和 AI 平台能力。
如果只是把训练任务作为普通 Pod 运行,早期可以满足基础需求,但当任务数量和团队规模上升后,就需要更细粒度的资源治理和调度策略。