GPU推理成本优化要从服务画像、峰谷流量、显存占用、弹性策略和成本归因逐步复盘。
很多推理服务为了保障峰值长期独占GPU,低峰时利用率很低。问题不是简单浪费,而是团队缺少延迟、冷启动和成本之间的权衡依据。


相关主题可以结合 Kubernetes、AI基础设施、云原生安全 和 GPU调度 等站内内容一起阅读。
1. 背景:低峰空闲但不敢缩容
很多推理服务为了保障峰值长期独占GPU,低峰时利用率很低。问题不是简单浪费,而是团队缺少延迟、冷启动和成本之间的权衡依据。
复盘要讲清背景、选择、过程、结果和可复用经验。
2. 先补服务画像
服务画像包括模型大小、显存常驻、QPS峰谷、P95延迟、错误率、调用方和SLO。没有画像就直接缩容,很容易影响线上稳定性。
复盘要讲清背景、选择、过程、结果和可复用经验。

3. 把服务分成三类处理
高峰稳定且延迟敏感的服务保守优化;峰谷明显的服务优先做弹性;离线或批量推理可以评估队列化和批处理。
复盘要讲清背景、选择、过程、结果和可复用经验。
4. 弹性策略要观察冷启动
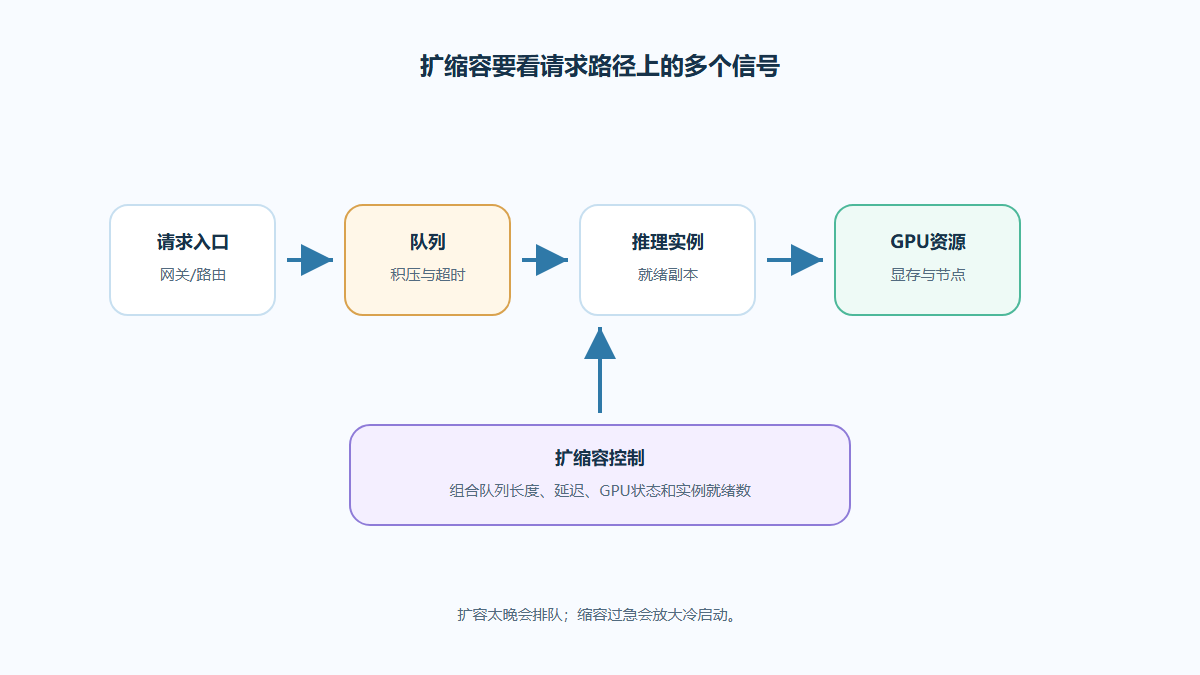
GPU推理冷启动可能涉及镜像拉取、模型加载和显存预热。扩缩容策略必须把这些时间纳入SLO评估。
复盘要讲清背景、选择、过程、结果和可复用经验。
| 检查项 | 关注点 | 风险信号 |
|---|---|---|
| 场景 | 是否匹配当前团队阶段 | 只按工具名判断 |
| 边界 | 是否说明适用条件 | 所有环境套一套方案 |
| 验证 | 是否能复测和回滚 | 只看一次演示结果 |
5. 成本归因推动持续优化
按服务、租户和时间段展示GPU成本后,业务团队才能理解低峰独占的代价,并参与优化决策。
复盘要讲清背景、选择、过程、结果和可复用经验。

6. 复盘结论要沉淀为平台能力
一次优化结束后,应把资源模板、弹性策略、监控面板和成本报表固化到平台,而不是依赖个人经验。
复盘要讲清背景、选择、过程、结果和可复用经验。
深入落地说明
1. 复盘先写清成本构成
GPU推理成本不只来自GPU小时数,还包括显存常驻、低峰空闲、冷启动预留、镜像和模型加载时间。复盘时要把这些成本拆开,才能找到优化入口。
如果只看总费用,团队会倾向于简单缩容;如果看清峰谷和显存占用,就能选择更细的弹性策略。
2. 服务分层决定优化方式
延迟敏感的在线服务、低频内部服务、批量推理任务适合不同策略。在线服务要谨慎调整副本和冷启动,批量任务可以更积极使用队列和批处理。
分层后可以先选低风险服务试点,验证效果后再推广到更关键的服务。
3. 弹性伸缩要考虑模型加载
GPU推理扩容不是启动容器这么简单,模型加载和显存预热可能占用较长时间。弹性策略要把预热时间纳入判断,否则扩容赶不上流量峰值。
可以结合预测扩容、最小副本和请求队列缓冲,减少低峰浪费同时保护峰值延迟。
4. 显存复用要有隔离边界
多模型共部署和显存复用能提高利用率,但也可能带来性能干扰。上线前要验证延迟、吞吐、错误率和模型加载失败时的隔离效果。
不要为了利用率牺牲关键服务SLO。高价值服务可以保守,低风险服务可以更激进。
5. 成本报表要能推动行动
报表应按服务、团队、时间段和GPU型号展示成本,并标出低峰空闲和长期独占资源。这样业务团队能看到具体优化对象。
复盘结论要落到平台能力,例如默认模板、弹性策略、监控面板和成本提醒,而不是停留在一次人工优化。
复盘步骤:从一次优化沉淀平台能力
- 还原背景:写清服务类型、调用峰谷、显存占用、延迟目标和原始成本。
- 分类服务:把服务分成延迟敏感、峰谷明显、批量推理和实验任务四类。
- 选择策略:分别评估弹性伸缩、批处理、显存复用、多模型共部署和低峰降配。
- 验证影响:对比优化前后的GPU成本、P95延迟、错误率、冷启动和业务反馈。
- 固化能力:把成功经验写入平台模板、弹性策略、监控面板和成本报表。
案例复盘要能复用。读者不是只想知道某次优化成功,而是想知道哪些条件下可以复制,哪些条件下不能复制。
场景化展开:GPU推理成本优化要守住延迟边界
1. 先区分推理服务类型
GPU推理成本优化不能把所有服务放在同一个策略里。延迟敏感在线服务、峰谷明显的业务接口、批量推理任务和实验模型,对成本和稳定性的权衡不同。延迟敏感服务更关注P95和P99,批量任务更关注吞吐和排队,实验模型则更适合低优先级资源。
分类之后再决定是否使用弹性伸缩、批处理、显存复用、多模型共部署或低峰降配。没有分类,优化动作很容易影响关键服务。
2. 显存复用要和故障隔离一起评估
多模型共部署和显存复用可以提升资源利用率,但也可能带来互相影响。一个模型加载失败、请求突增或内存泄漏,可能影响同卡上的其他服务。优化前需要明确隔离边界、限流策略、健康检查和回滚方式。
建议先在低风险模型上试点,观察GPU显存、计算利用率、延迟尾部、错误率和冷启动变化。指标稳定后,再扩大到相似服务,而不是直接覆盖所有推理入口。
3. 成本报表要能解释变化来源
推理成本下降后,平台团队需要回答下降来自哪里:副本减少、低峰缩容、批处理合并、模型共部署,还是任务迁移到更合适的GPU型号。只有能解释来源,优化经验才能复用。
复盘报告应同时写出限制条件。例如某个策略适合峰谷明显服务,却不适合全天低延迟接口;某个显存复用方案适合小模型,却不适合大模型长上下文。这样案例才不会被误用。
4. 优化前后要保留同口径对比
GPU推理成本优化需要同口径数据,否则结论容易失真。优化前后应使用相同时间窗口、相似流量结构、相同延迟统计口径和一致的成本归因规则。若流量在优化期间发生明显变化,需要在报告中单独说明。
对比表至少包含GPU成本、显存使用、P95/P99延迟、错误率、冷启动次数、扩缩容次数和业务反馈。只有成本下降且服务指标仍在边界内,优化才算真正成立。
5. 优化策略要保留业务解释口径
GPU推理成本优化通常会影响业务团队的使用方式,例如请求排队、冷启动、模型加载时间和低峰资源保留。平台团队需要提前解释优化目标、指标边界和例外处理方式,避免业务团队只看到资源被压缩。
如果某个服务必须保留独占GPU,也应把原因写清,例如低延迟、稳定吞吐、监管隔离或模型特殊依赖。成本治理不是所有服务同一策略,而是在业务边界内找到可优化空间。
落地检查清单
- 先确认本文讨论的问题是否就是当前团队的主要矛盾。
- 再检查现有平台、流程和人员职责是否支持这些动作。
- 最后用小范围验证替代一次性大改,保留回滚窗口和复盘记录。
小结
GPU推理成本优化复盘:从独占部署到弹性调度 的重点,是把读者正在搜索的问题落到真实场景、判断口径和执行顺序中。内容不应该停留在概念解释,也不应该把所有场景压成同一种答案。
发布和复盘时,可以重点检查三件事:标题承诺是否被正文兑现,图表是否帮助读者理解关键链路,FAQ是否回答了真实疑问。
常见问题
1. 这类问题应该先看工具还是先看场景?
建议先看场景。工具能力只有放到团队规模、业务风险、现有平台和运维流程中,才知道是否真的适合。
2. 如果测试环境能跑通,是否可以直接上生产?
不建议。生产环境还要验证权限、观测、告警、回滚、容量和多人协作流程,否则上线后问题会集中暴露。
3. 如何判断这篇文章中的方法是否适合自己的团队?
可以从目标、约束和验证成本三方面判断:目标是否一致,约束是否相近,是否能用小范围实验验证结论。