模型训练与推理部署
如果你正在把模型从实验推向生产,可以从训练任务、模型评估、模型部署、推理服务、性能优化和运行监控几个方向进入。这个分类更关注模型如何稳定、高效、可持续地运行在企业环境中。
-
vLLM Kubernetes部署怎么做?配置GPU推理服务
想把 vLLM 从单机示例放到 Kubernetes 上运行,难点通常不在启动命令,而在 GPU、模型文件、服务访问和运行状态验证。这篇文章按部署链路拆解可参考的配置思路。
-
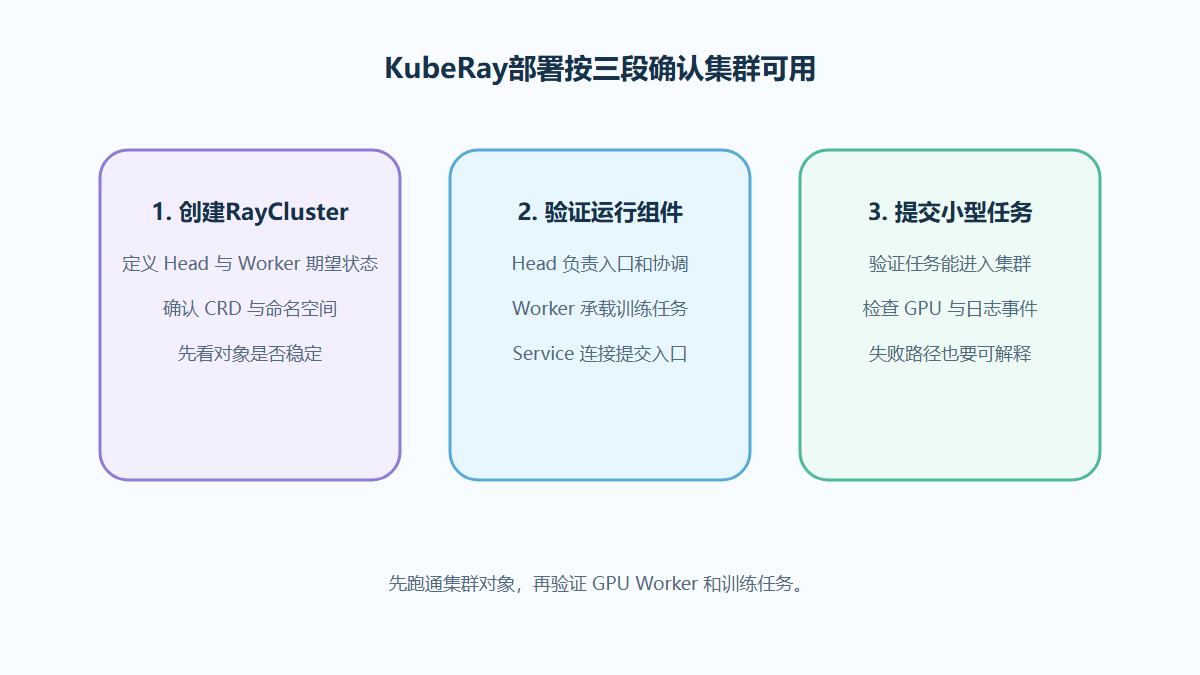
KubeRay部署Ray集群的GPU调度步骤
想用 KubeRay 在 Kubernetes 上跑 Ray 集群,不能只看 RayCluster 是否创建成功。本文从 Head/Worker、GPU申请、训练任务提交和状态验证入手,梳理平台团队可落地的部署步骤。
-
KServe vLLM区别怎么判断?服务层对比方法
纠结 KServe 和 vLLM 怎么选时,先别急着做二选一。一个更偏模型服务层,一个更偏推理执行层;读完本文可以用层级、职责和场景矩阵判断它们在平台中的位置。
-
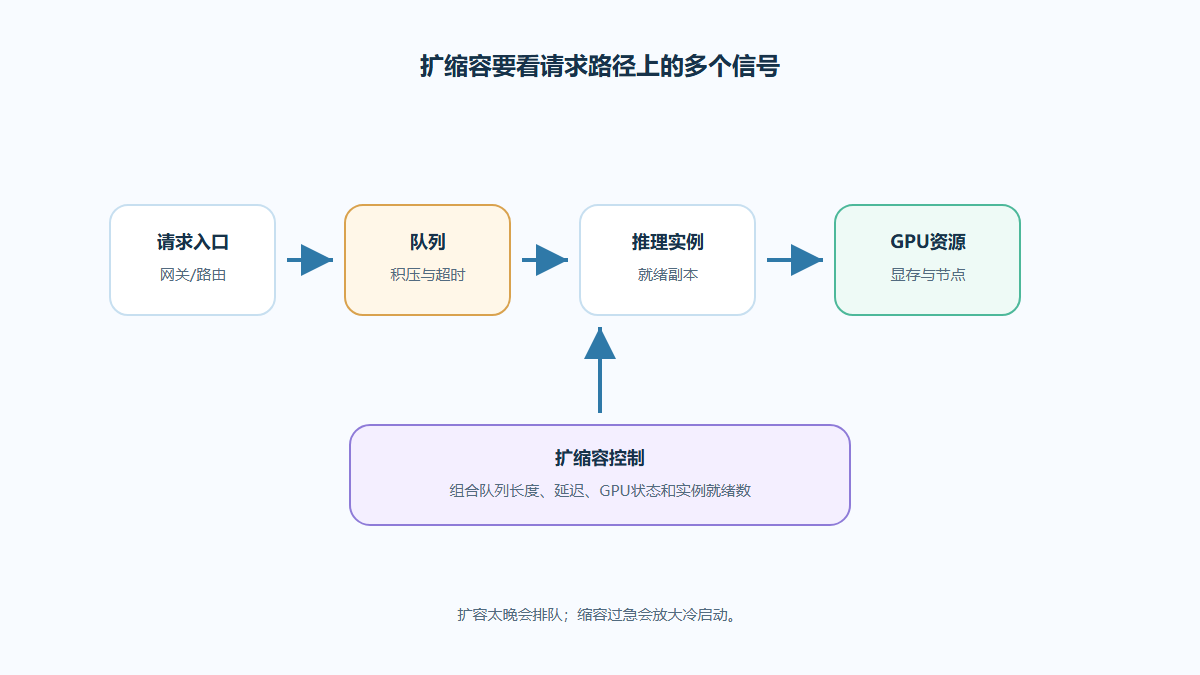
K8s模型推理扩缩容:HPA、队列、冷启动
推理服务明明开了 HPA,却还是排队、冷启动或 GPU 利用率异常?这篇内容把 CPU、队列、显存和模型加载放在同一条链路里看,给出 K8s模型推理扩缩容的判断框架和落地边界。
-
GPU推理副本数设置怎么做?显存判断方法
GPU推理副本数设置容易被 QPS、显存和冷启动同时影响。本篇用单副本显存、并发拐点、GPU调度边界和上线验证流程,帮助团队先定保守初始值,再通过压测和真实流量校准。
-
大模型训练流程怎么走?从数据到发布步骤
从数据集、GPU 资源到模型发布,大模型训练容易卡在版本、权限、评测和产物管理上。本篇按阶段拆解大模型训练流程,帮助你判断哪些步骤适合先平台化,哪些边界需要保留人工确认。
-
GPU推理成本优化复盘:从独占部署到弹性调度
当GPU推理服务长期独占资源、低峰空闲明显时,成本优化不能只靠降配。本文复盘从资源画像、请求峰谷、显存复用、弹性伸缩到成本归因的治理过程,帮助团队找到可持续优化路径。
-
LLM vs SLM:大语言模型与小模型怎么选?
读完本文,你可以建立《LLM vs SLM:大语言模型与小模型怎么选?》的评估框架,并判断当前更该优先关注哪些能力、架构与取舍。
-
边端推理崛起:LPU在具身智能与终端侧的应用前景
读完本文,你可以快速把握《边端推理崛起:LPU在具身智能与终端侧的应用前景》的关键问题与落地重点,并判断当前更值得优先推进哪些能力。
-
医疗大模型私有化部署:满足等保2.0与HIPAA合规的AI平台
读完本文,你可以梳理《医疗大模型私有化部署:满足等保2.0与HIPAA合规的AI平台》的关键步骤与落地重点,并判断当前最该先补哪一层能力。
-
政务大模型私有化部署方案:安全、合规与平台架构设计
读完本文,你可以梳理《政务大模型私有化部署方案:安全、合规与平台架构设计》的关键步骤与落地重点,并判断当前最该先补哪一层能力。
-
金融行业大模型私有化部署怎么做?合规、算力与运营要点
读完本文,你可以梳理《金融行业大模型私有化部署怎么做?合规、算力与运营要点》的关键步骤与落地重点,并判断当前最该先补哪一层能力。
-
大模型微调工具怎么选?LoRA、QLoRA与DeepSpeed适配分析
读完本文,你可以建立《大模型微调工具怎么选?LoRA、QLoRA与DeepSpeed适配分析》的评估框架,并判断当前更该优先关注哪些能力、架构与取舍。
-
GPU推理优化技术有哪些?TensorRT、vLLM与连续批处理实践
读完本文,你可以梳理《GPU推理优化技术有哪些?TensorRT、vLLM与连续批处理实践》的关键步骤与落地重点,并判断当前最该先补哪一层能力。
-
大模型分布式训练架构怎么设计?千卡级GPU集群的挑战与方案
读完本文,你可以快速把握《大模型分布式训练架构怎么设计?千卡级GPU集群的挑战与方案》的关键问题与落地重点,并判断当前更值得优先推进哪些能力。
-
分布式训练框架怎么选?PyTorch DDP、DeepSpeed、Megatron-LM对比
读完本文,你可以建立《分布式训练框架怎么选?PyTorch DDP、DeepSpeed、Megatron-LM对比》的评估框架,并判断当前更该优先关注哪些能力、架构与取舍。
-
分布式训练调度策略怎么选?数据并行、模型并行与流水线并行
读完本文,你可以建立《分布式训练调度策略怎么选?数据并行、模型并行与流水线并行》的评估框架,并判断当前更该优先关注哪些能力、架构与取舍。
-
模型推理平台怎么选?低延迟与弹性伸缩要点
读完本文,你可以建立模型推理平台的评估框架,并识别低延迟、弹性伸缩和服务治理中最该重点看的能力。
-
vLLM K8s部署怎么做?关键步骤与实践要点
读完本文,你可以快速掌握 vLLM 在 Kubernetes 上的部署重点,并理解资源配置、服务接入和运行治理中的常见注意事项。
-
大模型推理部署怎么做?架构设计与上线流程
读完本文,你可以梳理大模型推理部署从架构设计、资源准备到上线治理的关键步骤,并判断平台化部署的重点在哪里。










模型训练与推理部署常见问题
模型训练和模型推理对平台要求有什么不同?
模型训练更关注数据吞吐、GPU 并行、任务队列、检查点和实验追踪;模型推理更关注在线延迟、吞吐、弹性伸缩、灰度发布和稳定性。两类工作负载都需要算力,但调度和运维重点不同。
平台设计时应把训练任务和推理服务分开建模。训练可以偏批处理和队列化,推理则需要面向服务等级、监控告警和快速回滚。
LLM和SLM选型要看哪些因素?
LLM 通常能力更强,适合复杂推理、泛化能力要求高的场景;SLM 更轻量,适合成本敏感、低延迟、私有化和特定领域任务。选择时不能只看模型参数规模,还要看数据安全、部署环境、调用成本和效果评估。
企业常见做法是用大模型处理复杂理解和生成,用小模型处理固定、频繁、边界清晰的任务。这样可以在效果、成本和性能之间取得更稳定的平衡。
模型部署上线前需要验证什么?
上线前应验证模型版本、输入输出格式、延迟、吞吐、资源消耗、异常处理、灰度策略和回滚路径。对于大模型应用,还要验证安全边界、敏感信息处理和评估集表现。
不要只用少量人工样例判断模型可用性。生产环境需要持续评估和监控,否则模型上线后很难发现效果漂移、成本上升或异常输出。
推理服务成本为什么容易失控?
推理成本受模型规模、请求量、上下文长度、并发、缓存策略和硬件利用率影响。大模型应用如果缺少限流、缓存、模型路由和调用审计,成本会随着业务使用快速上升。
治理上可以结合模型分层、批处理、缓存、量化、弹性伸缩和调用配额。成本优化不是单点降配置,而是要在效果、延迟和资源之间做整体设计。