算力调度
算力调度是把 GPU、CPU、NPU 等计算资源按任务需求、优先级、配额和运行状态进行分配与编排的能力,用于提升 AI 训练、推理和批处理任务的资源利用率。
显示更多
在 AI 场景中,算力调度不只是“把任务放到某台机器上”。它还要解决资源碎片、排队等待、任务抢占、显存不足、多团队配额、故障迁移和成本归因等问题。
本页聚合算力调度、GPU调度、异构算力、AI集群管理和资源利用率优化相关内容,适合正在建设 AI 训练平台、推理资源池或企业算力平台的团队阅读。
- 覆盖 GPU调度、异构算力、任务排队、资源池化、弹性伸缩和配额治理
- 帮助分析 AI 集群中的资源利用率、等待时间、任务成功率和成本归因问题
- 关联 AI基础设施、模型训练、模型推理 和 Kubernetes 调度能力
企业级算力调度不只是把任务分配到空闲 GPU 上,而是要在多团队、多任务类型和有限资源之间持续优化。成熟平台通常需要支持队列管理、优先级策略、资源配额、任务抢占、GPU 拓扑感知、弹性伸缩、失败重试、监控告警和成本归因。对企业来说,关键不是“能不能调度”,而是能否在训练、推理、批处理等不同负载之间保持资源利用率、任务成功率和业务优先级的平衡。
算力调度常见于大模型训练、批量推理、在线推理资源池、AutoML、数据处理任务和多团队共享 GPU 集群。训练任务更关注排队策略、长任务容错和拓扑亲和性;在线推理更关注弹性伸缩、低延迟和资源隔离;批处理任务则更关注吞吐、成本和空闲资源利用。不同用例对应的调度策略不同,不能只用一套简单的资源分配规则处理所有任务。
GPU调度是算力调度的重要组成部分,但算力调度的范围更大。GPU调度重点解决显卡分配、显存、拓扑、MIG/vGPU 和多卡通信效率问题;算力调度还要处理队列、优先级、团队配额、弹性策略、任务生命周期、成本归因和跨资源池治理。企业建设 AI 平台时,通常需要把 GPU 调度纳入更完整的算力调度体系中。
学习路径
-
K8s中GPU共享怎么选?MIG与时间片选择框架
一张GPU卡到底该切成固定实例,还是让多个任务轮流使用?围绕K8s GPU共享,本篇从隔离、显存、性能抖动和租户体验拆解MIG与时间片的取舍,并给出上线前检查清单。
-
GPU资源碎片化治理:画像、配额与调度策略
GPU利用率看似不低,任务却仍在队列里等待,往往不是单点扩容能解决的问题。本篇从GPU资源碎片化治理出发,拆解画像、配额、队列和调度策略如何协同,让剩余算力更容易被真正使用。
-
K8s模型推理扩缩容:HPA、队列、冷启动
推理服务明明开了 HPA,却还是排队、冷启动或 GPU 利用率异常?这篇内容把 CPU、队列、显存和模型加载放在同一条链路里看,给出 K8s模型推理扩缩容的判断框架和落地边界。
-
K8s GPU Operator部署-3步验证节点
集群已经有 GPU 节点,却不知道 Operator 是否真正生效?这篇内容从驱动、Device Plugin、节点标签和 Pod 调度结果入手,给出可复用的 K8s GPU Operator 验证路径。
-
AI平台多租户配额怎么设计?设计租户和队列边界
当多个团队共用同一批 GPU 和模型环境时,AI平台多租户配额的难点常常不是资源本身,而是租户、队列、权限和借用规则没有说清。读完可获得一套可落地的治理检查路径。
-
GPU算力平台采购-5项POC验证点
GPU 资源紧张、团队抢卡和 AI 任务交付压力并存时,采购 POC 不能只跑通一个示例。本文围绕 GPU算力平台采购的 5 项验证点,拆解接入、调度、任务、观测和治理证据。
-
云原生AI基础设施架构-5层能力清单
AI应用从试点走向生产后,平台团队往往同时面对算力排队、模型追溯、推理发布和治理审计压力。本篇用5层能力清单拆解云原生AI基础设施,帮助你快速定位架构短板和下一步建设重点。
-
企业AI平台建设:权限、算力与模型资产
模型、数据集、GPU 队列和推理服务分散在不同系统时,企业AI平台容易变成“能跑但难管”。本篇从项目权限、算力配额、模型版本和发布审计切入,帮助团队判断平台建设优先级。
-
GPU管理平台有哪些?灵雀云算力治理
GPU 资源越来越贵,真正难题往往不是“有没有平台”,而是谁能把卡型、队列、配额、租户和训练推理任务管起来。本篇聚焦灵雀云算力治理视角,帮助你评估 GPU管理平台该补哪些企业级能力。
-
万卡集群算力评审清单-资源池网络与调度联审
万卡集群算力评审不应只汇报 GPU 数量和预算。本文把规划材料拆成资源池、网络、存储、调度和验收证据,帮助多团队在扩容前对失败信号、责任边界和复盘口径达成一致。
-
GPU集群管理软件选型矩阵-5类方案与PoC清单
GPU集群管理软件选型不能只看控制台功能。本文把五类方案放到同一张矩阵中,帮助团队按任务规模、既有技术栈、集成成本和受控失败 PoC 判断哪类方案更适合当前阶段。
-
算力调度模型评审清单:队列配额如何落地
队列、配额和优先级真正上线后,争议通常来自策略解释、变更留痕和回滚条件。本文把算力调度模型拆成评审清单,帮助平台团队在上线前确认规则能被执行、审计和复盘。
-
GPU资源池怎么规划?节点分层、配额与隔离策略
GPU 资源池不是把所有显卡放进同一个集群就结束。不同型号、显存、网络、任务类型和业务等级会产生不同约束,规划不好会导致高端卡浪费、低优先级任务挤占核心服务。
-
GPU集群观测看什么?利用率、显存与容量风险
GPU 利用率高不一定代表资源健康,显存接近上限、排队时间变长、节点故障或资源碎片都会影响 AI 任务交付。GPU 集群观测要把资源、任务和容量风险放在一起看。
-
AI工作负载调度怎么做?训练、推理与优先级队列
AI 平台里既有长时间训练,也有低延迟推理,还有临时实验和批量生成任务。它们对 GPU、显存、网络、等待时间和稳定性的要求不同,调度策略必须分层设计。
-
AI平台多租户怎么做?资源隔离、权限与成本归因
当多个团队共用同一套 AI 平台时,最容易出现资源争抢、权限过宽、成本不清和故障影响扩散。多租户治理要让共享资源既能复用,又不会失去边界。
-
Kubernetes怎么做AI训练调度?GPU队列与多租户实践
面向建设 AI 训练平台的平台团队,本文从 GPU 资源池、任务队列、多租户配额、优先级抢占、数据访问和监控治理出发,说明 Kubernetes 如何支撑训练调度。
-
GPU算力调度平台怎么选:从资源池化到AI训练推理落地
GPU资源越来越贵,AI任务却越来越碎片化。本文围绕企业AI训练、推理和研发实验场景,拆解GPU算力调度平台在资源池化、队列策略、隔离共享、成本治理和云原生集成中的关键判断,帮助平台团队把算力从固定分配变成可运营资源。
-
GPU推理成本优化复盘:从独占部署到弹性调度
当GPU推理服务长期独占资源、低峰空闲明显时,成本优化不能只靠降配。本文复盘从资源画像、请求峰谷、显存复用、弹性伸缩到成本归因的治理过程,帮助团队找到可持续优化路径。
-
GPU利用率低怎么办?从资源画像到调度治理
GPU利用率低不是简单地多提交任务就能解决,背后通常有资源碎片、显存占用、队列拥塞、任务画像不清和低优资源无法回收等问题。本文从平台治理角度梳理诊断路径、优化顺序和持续运营指标。


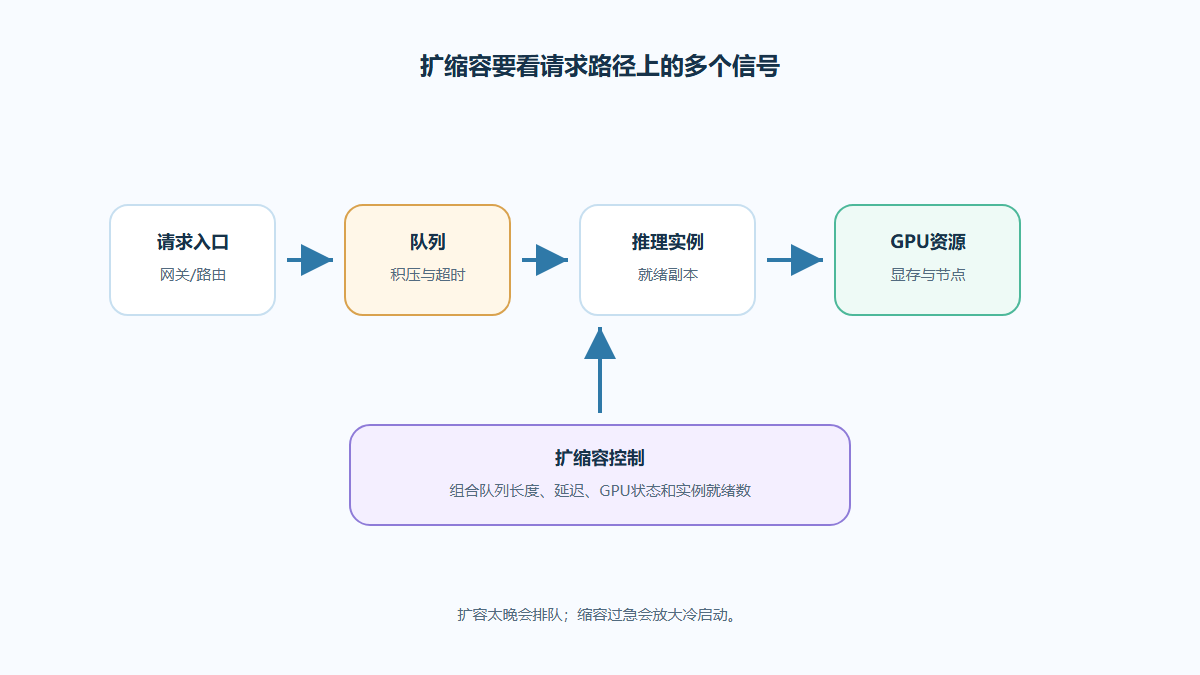

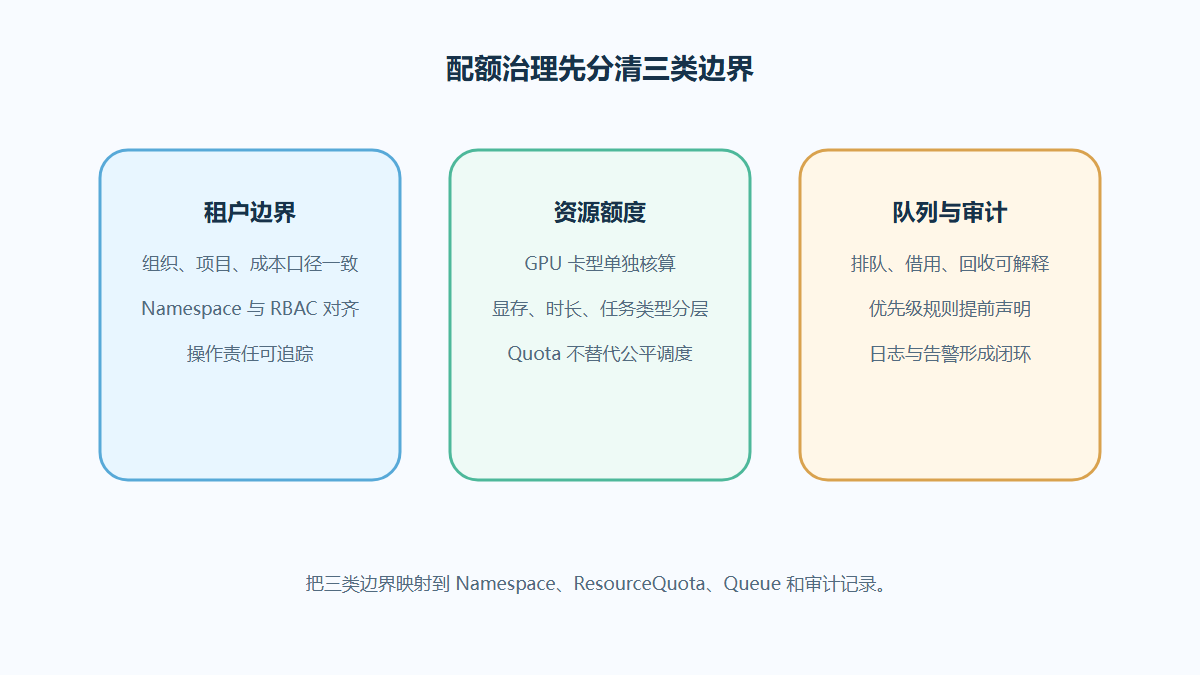















了解更多关于算力调度的信息
算力调度主要解决什么问题?
算力调度主要解决 AI 集群里的资源利用率、任务交付效率和多团队资源治理问题。没有统一调度时,经常会出现 GPU 空闲但任务排队、训练任务长期占用高价值资源、推理服务高峰期扩不起来、不同团队之间资源边界不清晰等情况。
一个有效的算力调度体系通常会把队列、配额、优先级、抢占、拓扑感知和监控数据结合起来,让平台能够判断:哪些任务应该先运行,哪些任务可以等待,哪些资源可以回收,哪些业务需要更稳定的资源保障。
Kubernetes 自带调度器够用吗?
算力调度如何帮助降低成本?
算力调度降低成本的核心不是简单减少 GPU 采购,而是提升已有算力的有效使用率。很多企业的真实浪费并不来自“没有机器”,而是来自资源被低优先级任务长期占用、任务排队策略不合理、资源申请粒度过大、空闲 GPU 没有及时回收,以及成本无法归因到团队或业务。
通过任务排队、空闲回收、弹性伸缩、配额控制和成本归因,平台可以减少资源闲置和重复申请。对于已经在建设 AI基础设施 的团队,算力调度往往是比单纯扩容更优先的成本治理入口。
建设算力调度平台前要先看哪些指标?
建议先看四类指标,而不是直接从产品功能清单开始选型:
- 资源效率指标:GPU 利用率、显存利用率、资源碎片率、空闲资源占比;
- 任务交付指标:任务等待时间、运行成功率、失败重试次数、长任务中断率;
- 业务治理指标:团队配额使用情况、优先级执行效果、抢占影响范围;
- 推理稳定性指标:峰谷波动、扩缩容时间、延迟和吞吐变化。
这些指标能帮助判断问题到底是资源总量不足,还是调度策略、队列机制和平台治理不足。前者需要扩容,后者更适合通过算力调度和平台化治理解决。