GPU显存不足排查的第一步不是“换更大的卡”,而是确认显存不足发生在哪个层级:Pod 是否拿到了 GPU、模型是否超出显存预算、并发或 batch size 是否放大占用、节点上是否还有其他负载竞争资源。下面从现象到预防逐层定位。
GPU显存不足先看现象和影响范围
先判断问题是单个 Pod、某个模型、某类节点,还是整个 GPU 节点池。不同范围对应不同处理动作。
建议优先收集这些信息:
- Pod事件:是否出现调度失败、重启、驱逐或资源不足提示。
- 容器日志:是否有 CUDA out of memory、模型加载失败或运行时异常。
- 节点资源:GPU 是否被多个工作负载占用,显存是否接近上限。
- 请求特征:是否在高并发、长上下文或大 batch 时复现。
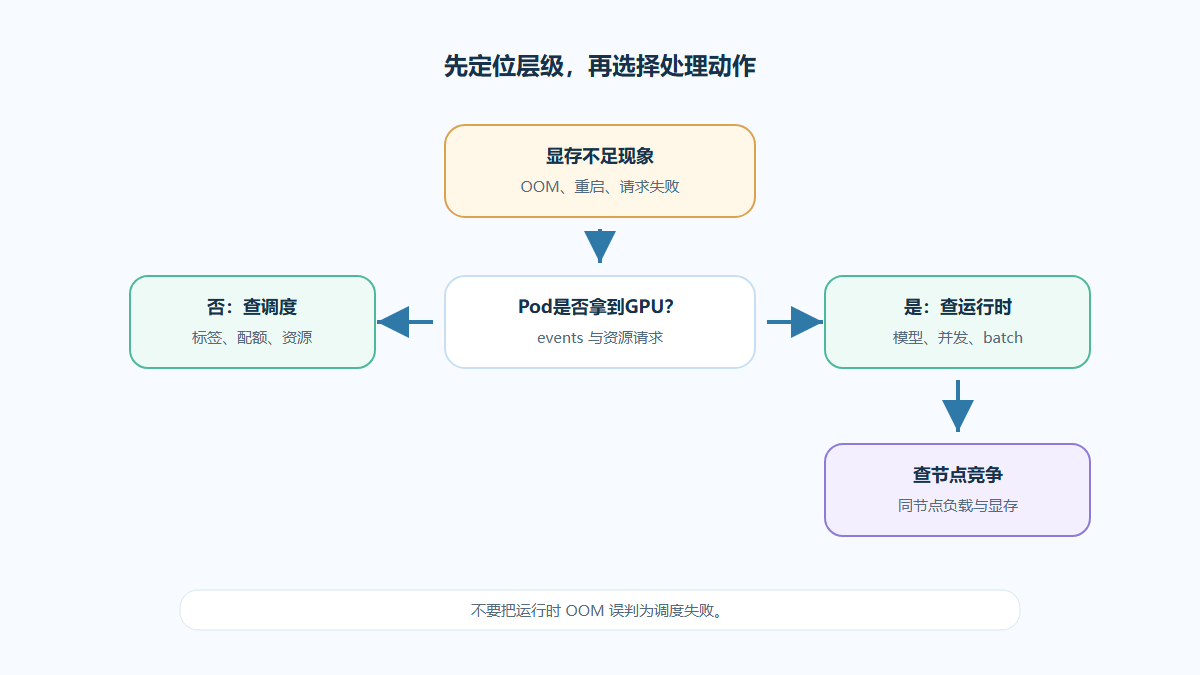

图1:显存不足排查决策树应先定位 Pod、模型参数、并发和节点
在 GPU调度 场景中,调度只能决定 Pod 放到哪里,不能自动保证模型显存一定够用。因此要把“资源被调度到节点”和“模型运行时显存足够”分开判断。
第一步定位是Pod配置还是模型参数
如果 Pod 没有正确申请 GPU,问题会先表现为调度失败或运行时无法访问设备;如果 Pod 已经拿到 GPU,但模型加载或请求执行时报错,重点就转向模型参数和显存占用。
kubectl describe pod <pod-name> -n <namespace>
kubectl logs <pod-name> -n <namespace> --previous
kubectl describe node <gpu-node-name>| 信号 | 更可能的问题 | 下一步 |
|---|---|---|
| Pod Pending | GPU 资源、节点选择或配额限制 | 查 events、节点标签、配额 |
| Pod Running 但报 OOM | 模型或并发超出显存预算 | 查日志和模型参数 |
| 容器重启 | 启动参数、显存或探针异常 | 查 previous logs |
| 同节点多个任务异常 | 节点资源竞争或监控口径不足 | 查节点 GPU 使用状态 |
不要把运行时错误误判为调度错误
如果 Pod 已经调度到 GPU 节点且设备可见,后续 CUDA OOM 更可能与模型大小、batch、上下文长度、并发或缓存有关。此时反复调整 nodeSelector 通常不能解决问题。
第二步检查并发、batch size和显存占用
显存占用不是只由模型大小决定。请求并发、batch size、上下文长度、缓存策略和框架实现都会影响运行时峰值。对于 模型推理 服务,峰值往往出现在请求集中进入或模型刚加载完成后的压力阶段。

图2:同样是显存不足,根因可能来自模型、并发、资源请求或节点状
可以按三个方向收敛:
- 降低单实例并发或 batch,观察是否稳定。
- 缩短上下文、减少缓存压力或调整模型加载策略。
- 将模型拆分到更合适的节点池或使用更明确的资源隔离。
这些动作都应先在测试或灰度环境验证,不建议在生产高峰期直接大幅修改并发和模型参数。
第三步确认节点资源和调度结果
如果多个 Pod 共享同类 GPU 节点,显存不足也可能来自节点上其他工作负载。Kubernetes 默认只按资源请求调度,不一定理解每个模型运行时显存峰值,因此平台要把节点状态和应用指标结合起来看。
排查节点侧时关注:
- 节点是否存在多个 GPU 工作负载同时运行。
- GPU 资源是否被正确上报,Pod 是否使用了预期设备。
- 命名空间或队列是否存在配额限制。
- 监控是否能看到显存使用、重启次数和请求失败。
资源请求只是调度入口,不是显存预算
`nvidia.com/gpu: 1` 表示 Pod 申请一张 GPU,并不说明这张卡上的显存一定足够你的模型和并发。显存预算需要结合模型、请求和运行时单独评估,并在上线前记录假设条件。
如何降低显存不足再次发生的概率
显存不足不应只靠故障时手工处理。更稳定的方式是把显存预算、并发上限、模型变更和监控告警纳入发布流程。

图3:上线前要把显存预算、并发上限和监控指标一起校准
上线前至少检查:
- 显存预算:模型加载和峰值请求是否在可接受范围内。
- 并发边界:最大并发、batch 和上下文长度是否有上限。
- 节点隔离:关键模型是否使用专用节点池或队列策略。
- 告警信号:显存、重启、请求失败和延迟是否可观测。
- 回滚条件:模型参数或并发调整失败时如何快速恢复。
小结
GPU 显存不足排查要先确认影响范围,再区分 Pod 配置、模型参数、并发和节点资源。调度层决定 Pod 是否获得 GPU,运行时层决定模型和请求是否能在显存内稳定执行。
当问题复现时,先看事件和日志,再看模型参数和并发,最后确认节点资源和配额策略。长期治理则需要显存预算、观测指标和发布前检查清单,而不是每次故障都临时加卡。
常见问题
1. GPU显存不足排查应该先看日志还是节点?
先看 Pod events 和日志,再看节点。events 可以判断是否调度失败,日志可以判断是否模型加载或运行时 OOM。只有明确 Pod 已经拿到 GPU 后,节点显存和其他负载才是下一步重点。
2. CUDA OOM一定说明GPU资源不够吗?
不一定。CUDA OOM 可能来自模型过大、并发过高、batch size 不合适、上下文过长或显存碎片。是否需要增加 GPU,要在确认模型和参数已经合理后再判断。
3. 降低batch size会影响推理服务吗?
可能会影响吞吐和延迟表现,但能降低单次显存峰值。建议在测试环境用真实请求模式验证,而不是直接套用固定数值。目标是在显存稳定和服务体验之间取得平衡。
4. Kubernetes能自动防止显存不足吗?
Kubernetes 可以根据资源请求调度 GPU,但不能完全理解模型运行时显存峰值。要降低风险,需要应用指标、GPU 监控、并发限制和平台配额共同配合。




