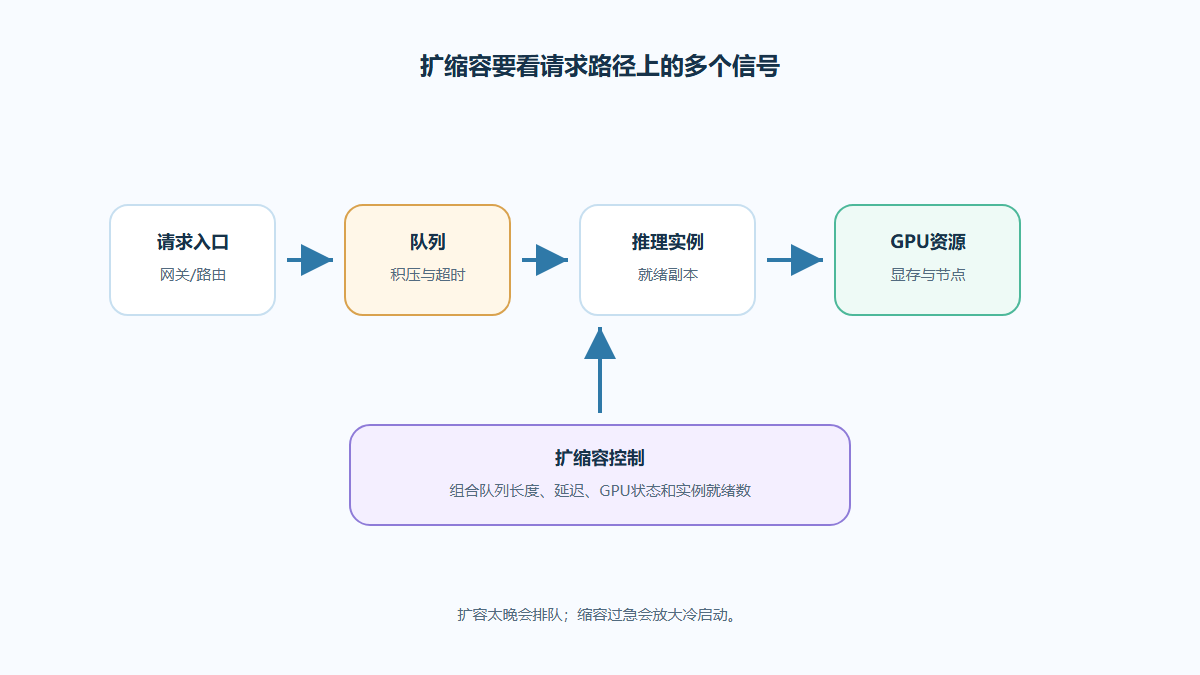
适用场景:本文面向希望在 Kubernetes 上运行 vLLM 推理服务的平台、算法工程和运维团队;示例只提供通用配置思路,不替代你所在环境的镜像、模型仓库和安全策略。
vLLM Kubernetes部署的目标不是把一个推理进程“拉起来”,而是让模型、GPU、网络访问和运行状态都能被平台稳定管理。真正要设计的是一条推理服务链路:模型从哪里来,Pod 怎么申请 GPU,Service 怎么暴露,失败时如何观察和恢复。
vLLM Kubernetes部署先看目标架构
在 Kubernetes 中部署 vLLM,通常至少涉及 Deployment 或自定义工作负载、GPU 节点、模型存储、Service、探针和日志指标。它属于 模型推理 链路的一环,但比普通 Web 服务多了显存、模型加载时间和并发配置等约束。


图1:vLLM推理服务整体架构图需要同时处理模型、GPU、Se
建议先明确四个问题:
- 模型来源:模型文件是挂载、预置到镜像,还是从模型仓库拉取。
- GPU约束:单个 Pod 需要多少 GPU,是否需要指定节点池。
- 服务入口:内部调用、网关暴露还是批量任务调用。
- 验证口径:用日志、探针、请求返回和 GPU 使用状态共同判断部署成功。
推理服务需要哪些K8s对象
vLLM 服务可以从一组基础 Kubernetes 对象开始:工作负载负责运行推理进程,Service 提供访问入口,ConfigMap 或 Secret 承载非敏感和敏感配置,PVC 或对象存储侧载提供模型文件。
| 对象 | 作用 | 设计重点 |
|---|---|---|
| Deployment / StatefulSet | 运行 vLLM 服务实例 | 副本、滚动更新、探针和资源请求 |
| Service | 暴露服务访问入口 | 端口命名、访问范围、调用路径 |
| ConfigMap / Secret | 管理启动参数和凭据 | 避免把敏感信息写入镜像或明文 YAML |
| PVC / 模型存储 | 提供模型文件 | 加载速度、缓存策略和权限控制 |
工作负载对象要匹配模型加载方式
如果模型较大,启动时间可能明显长于普通应用。此时探针要考虑模型加载阶段,不宜用过短的失败阈值把正常初始化误判为不可用。推理服务的健康检查应区分进程存活、模型就绪和请求可用,不要只依赖容器启动状态。
GPU资源和模型路径怎么配置
GPU 配置应通过资源请求、节点选择和容忍策略表达,而不是只在启动命令里假设节点可用。模型路径则要根据团队的模型分发方式设计,常见方式包括挂载共享存储、 init 容器预拉取、镜像内置轻量模型或从平台模型仓库同步。
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-runtime
spec:
replicas: 1
selector:
matchLabels:
app: vllm-runtime
template:
metadata:
labels:
app: vllm-runtime
spec:
nodeSelector:
accelerator: nvidia-gpu
containers:
- name: vllm
image: example/vllm-runtime:stable
args:
- "--model=/models/demo"
- "--host=0.0.0.0"
resources:
limits:
nvidia.com/gpu: "1"
ports:
- containerPort: 8000这段配置只展示结构,真实环境还需要结合镜像来源、模型权限、运行用户和网络策略调整。涉及 GPU调度 时,还要确认 GPU 节点标签、资源上报和队列策略不会阻断 Pod 调度。

图2:GPU资源请求、显存占用和并发参数会共同影响推理服务稳定
服务暴露、探针和观测怎么设计
vLLM 部署完成后,服务访问只是第一步。平台团队还需要知道服务是否正在加载模型、是否因为显存不足退出、请求延迟是否异常、日志里是否出现模型路径或权限错误。
推荐观察这些信号:
- Pod phase、重启次数和事件。
- 容器日志中的模型加载、端口监听和错误信息。
- GPU 使用率、显存占用和节点剩余资源。
- Service 端点是否正确指向就绪 Pod。
- 探针是否区分存活和就绪状态。
不要把探针写成重启放大器
如果 readinessProbe 过严,流量可能一直进不来;如果 livenessProbe 过急,模型加载期间可能被反复重启。更稳妥的做法是先给启动阶段留出合理窗口,再用就绪探针控制流量进入。
部署失败时先看哪些信号
部署失败不要从“换镜像”开始。先根据症状判断问题位于模型、GPU、网络还是运行参数。
| 现象 | 常见方向 | 检查方法 |
|---|---|---|
| Pod Pending | GPU 资源或节点约束不满足 | `kubectl describe pod` 查看事件 |
| Pod Running 但不可访问 | Service 或端口配置不匹配 | 查看 Endpoints、端口和网络策略 |
| 容器反复重启 | 模型路径、显存或启动参数异常 | 查看 logs 与 previous logs |
| 首次请求很慢 | 模型加载或冷启动影响 | 区分启动耗时和稳定态耗时 |

图3:部署完成后要验证服务访问、GPU使用、日志和探针状态
小结
vLLM Kubernetes部署要同时处理模型文件、GPU 资源、服务入口和运行状态。先确认目标架构,再配置工作负载和资源请求,最后用服务访问、日志、GPU 状态和探针共同验证。
不要把示例 YAML 当成生产模板。生产环境更需要模型分发策略、权限控制、显存预算、扩缩容边界和观测信号,这些能力共同决定推理服务是否可长期运行。
常见问题
1. vLLM Kubernetes部署一定要使用GPU吗?
多数大模型推理场景会使用 GPU,但具体取决于模型规模、性能目标和测试目的。开发验证可以先用较小模型或受限资源验证链路,生产推理则应根据显存、并发和延迟目标设计 GPU 资源。
2. vLLM服务启动慢是不是部署失败?
不一定。模型加载、权重初始化和缓存准备都可能让启动耗时变长。判断时应查看日志和探针状态,区分“仍在加载”“模型路径错误”和“显存不足导致退出”。
3. vLLM Pod为什么一直Pending?
常见原因包括 GPU 资源不足、节点标签不匹配、污点容忍缺失、命名空间配额限制或调度策略阻断。先查看 Pod events,再检查节点 GPU 资源和平台配额。
4. vLLM部署后如何做后续优化?
先稳定基本链路,再逐步调整并发参数、批处理策略、模型缓存和扩缩容策略。涉及性能或成本判断时,应基于你自己的模型、节点和流量口径测试,不建议套用未验证的通用结论。