适用场景:本文面向需要 KubeRay部署Ray集群并承载 GPU 训练任务的团队;具体 CRD 字段和版本应以你所在环境为准,正文只保留通用部署与验证思路。
KubeRay部署Ray集群不只是创建一个 RayCluster 对象。平台团队还要确认 Head 和 Worker 如何运行、Worker Pod 如何申请 GPU、训练任务如何提交、以及任务失败时能否从 Kubernetes 和 Ray 两侧定位原因。
KubeRay部署Ray集群先看组件关系
Ray 集群在 Kubernetes 中通常由 Head 和 Worker 组成。Head 负责集群控制、任务入口和状态协调,Worker 负责实际执行任务。KubeRay 的作用是把这些关系转换为 Kubernetes 可管理的对象。
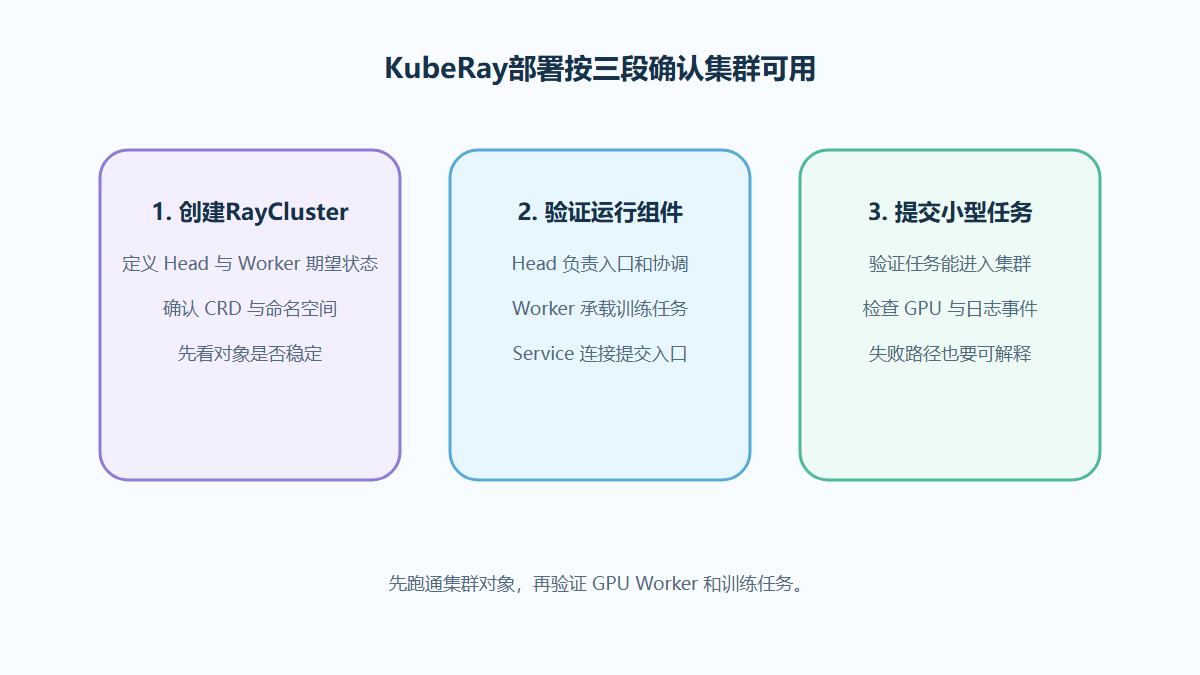

图1:Ray Head 和 Worker 在 Kubernet
如果你的场景偏 模型训练,KubeRay 更常被用于分布式训练、批处理和并行计算任务。此时 GPU 资源配置和任务排队方式会直接影响集群可用性。
Ray Head和Worker在K8s里怎么运行
理解 Head 和 Worker 的职责,有助于拆分问题。
| 组件 | 职责 | Kubernetes视角 | 常见检查点 |
|---|---|---|---|
| Ray Head | 集群入口、控制和任务协调 | Head Pod、Service | 是否 Running,端口是否可访问 |
| Ray Worker | 执行训练或计算任务 | Worker Pod | 副本数、资源请求、节点调度 |
| RayCluster | 描述集群期望状态 | 自定义资源 | spec 是否符合环境约束 |
| 任务提交入口 | 提交训练或批处理作业 | CLI、Job 或平台入口 | 任务是否进入 Ray 集群 |
先验证控制面,再验证训练任务
如果 Head Pod 不稳定,Worker 副本正常也无法形成可靠集群;如果 Head 正常但任务无法使用 GPU,再检查 Worker 的资源请求、节点选择和任务参数。不要把任务失败都归因于 Ray 本身,Kubernetes 调度和资源配置同样关键。
训练任务如何申请GPU资源
Worker Pod 是否能使用 GPU,取决于 Kubernetes 资源请求和节点调度。常见做法是在 Worker 模板中声明 GPU limit,并通过节点标签或队列策略把任务放到合适节点。
workerGroupSpecs:
- groupName: gpu-workers
replicas: 2
template:
spec:
nodeSelector:
accelerator: nvidia-gpu
containers:
- name: ray-worker
resources:
limits:
nvidia.com/gpu: "1"这只是结构示例。真实部署时还要结合镜像、启动命令、运行用户、存储挂载、网络策略和平台配额配置。涉及 GPU调度 时,建议把 Ray 任务和其他 GPU 任务放到统一资源治理口径中。

图2:训练任务能否使用 GPU,取决于 Worker Pod
部署后如何验证Ray集群可用
KubeRay 部署后,至少要验证 Kubernetes 对象、Ray 集群状态、GPU 资源和任务提交四件事。
验证顺序可以这样设计:
- 查看 RayCluster 状态和 Head / Worker Pod。
- 查看 Worker Pod 是否调度到 GPU 节点。
- 查看 Worker 容器是否能看到预期 GPU 设备。
- 提交一个小型任务,验证任务能运行并返回结果。
- 检查日志、事件和平台监控是否能定位异常。
kubectl get raycluster -n <namespace>
kubectl get pods -n <namespace> -o wide
kubectl describe pod <worker-pod> -n <namespace>任务验证要覆盖失败路径
只提交一个成功任务不够。建议至少覆盖资源不足、Worker 缩容、Head 重启和任务参数错误等失败路径,确认平台能给出可理解的事件、日志和告警。

图3:验证 Ray 集群要同时看 Head、Worker、任务
什么时候不建议单独做KubeRay专项部署
如果团队只是偶尔运行小规模任务,且没有分布式训练、并行计算或多团队共享需求,单独建设 KubeRay 可能带来额外运维复杂度。更适合先明确训练任务规模、资源隔离需求和平台治理目标。
更适合优先评估KubeRay的场景包括:
- 多个团队需要共享 GPU 训练资源。
- 任务需要弹性 Worker 或并行执行。
- 训练任务需要纳入统一队列、配额和观测体系。
- 平台希望把 Ray 集群生命周期交给 Kubernetes 管理。
小结
KubeRay 部署 Ray 集群的关键在于把 Ray 的 Head / Worker 模型和 Kubernetes 的 Pod / 资源 / 调度模型对齐。Head 负责入口和协调,Worker 承载任务执行,GPU 资源通过 Kubernetes 请求和节点策略进入训练链路。
落地时不要只检查 RayCluster 创建成功,还要验证 Worker 是否拿到 GPU、任务是否能提交、失败路径是否可观测。只有这些环节打通,Ray 集群才算真正进入平台治理。
常见问题
1. KubeRay部署Ray集群一定需要GPU吗?
不一定。Ray 可以运行 CPU 并行任务,也可以运行 GPU 训练任务。本文聚焦 GPU 调度步骤,是因为 AI 训练场景更常遇到资源申请、节点选择和显存治理问题。
2. Ray Head和Worker哪个更重要?
两者都重要,但排查顺序不同。Head 不稳定会影响集群入口和任务协调;Worker 不稳定会影响任务执行能力。通常先确认 Head 可用,再检查 Worker 资源和任务运行。
3. Worker Pod没有调度到GPU节点怎么办?
先查看 Pod events,确认是否缺 GPU 资源、节点标签不匹配、污点容忍缺失或配额不足。再检查 Worker 模板里的资源请求和 nodeSelector 是否符合集群策略。
4. KubeRay适合直接用于生产训练平台吗?
可以作为训练平台组件,但需要配合镜像管理、权限、队列、配额、日志、监控和失败恢复。是否适合生产,要看团队是否具备这些平台治理能力,而不是只看部署命令是否成功。



