AI平台与MLOps
如果你关注模型从开发到上线的工程化流程,可以从实验管理、模型仓库、训练任务、部署发布、评估监控和治理审计几个方向进入。这个分类更适合负责 AI 平台、算法工程和模型运维的团队阅读。
-
AI工作流编排怎么做?DAG与审批门设计
当AI应用从单次调用走向多步骤Agent任务时,流程失控、审批缺位和失败重跑会迅速放大风险。本篇从DAG节点拆分、人工审批位置、幂等重试、补偿回滚和平台治理清单切入,帮助读者判断哪些流程适合自动化,哪些动作必须保留人工门禁。
-
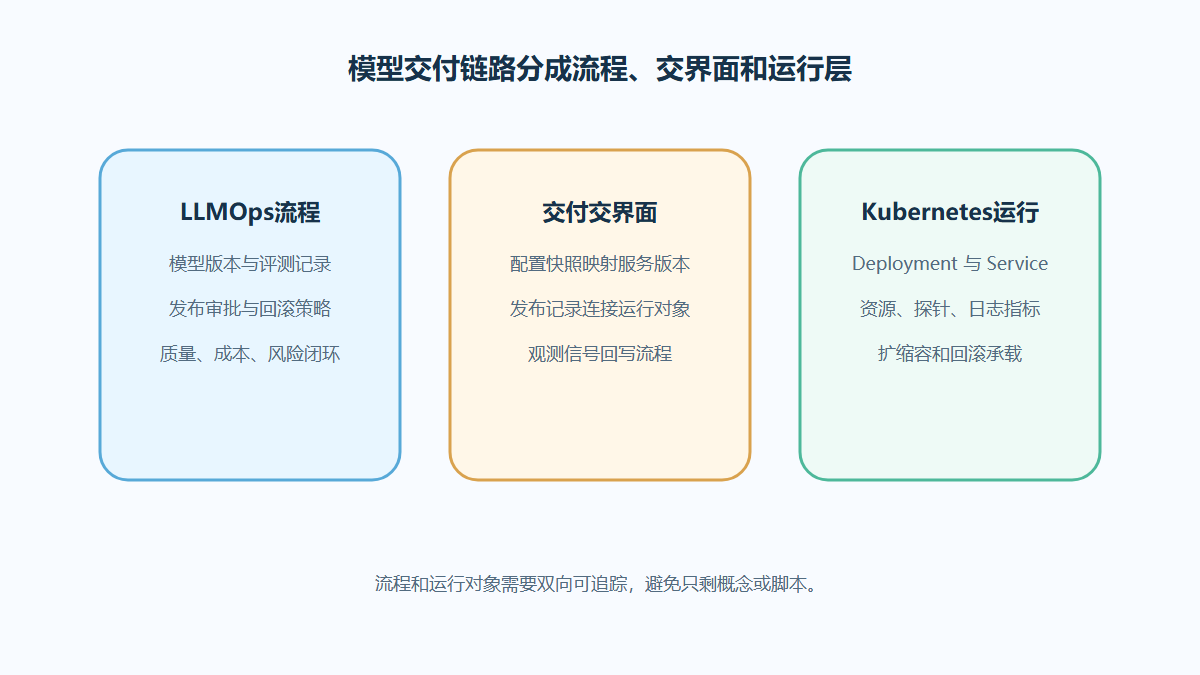
LLMOps Kubernetes模型交付链路设计
大模型上线不是把容器部署到集群就结束。围绕 LLMOps和Kubernetes 的分工,本文梳理模型从注册、发布、扩缩容到观测回滚的交付链路,让平台团队看清先补哪一段能力。
-
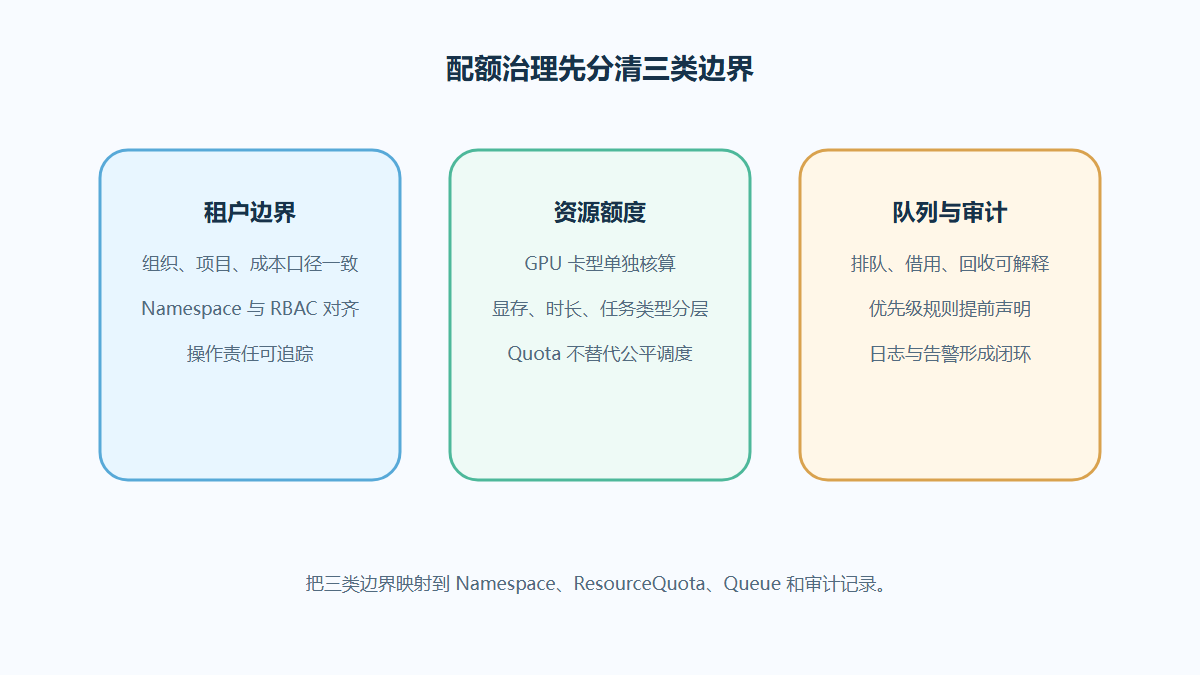
AI平台多租户配额怎么设计?设计租户和队列边界
当多个团队共用同一批 GPU 和模型环境时,AI平台多租户配额的难点常常不是资源本身,而是租户、队列、权限和借用规则没有说清。读完可获得一套可落地的治理检查路径。
-
企业AI平台建设:权限、算力与模型资产
模型、数据集、GPU 队列和推理服务分散在不同系统时,企业AI平台容易变成“能跑但难管”。本篇从项目权限、算力配额、模型版本和发布审计切入,帮助团队判断平台建设优先级。
-
运维大模型怎么落地?如何提升告警降噪与根因定位准确率
面向平台运维、SRE和AIOps建设团队,本文聚焦运维大模型落地路径,解释怎样把大模型真正嵌入告警处理与故障分析流程,而不是停留在问答演示层面。
-
智能运维平台怎么选?2026年主流AIOps方案与评估维度
这篇文章面向正在评估智能运维平台的企业团队,重点梳理AIOps平台的适用边界、核心能力和采购判断方法,帮助你避免只看功能清单却忽略治理体系的常见误区。
-
智算中心是干什么的?建设目标、服务模式与企业应用场景解析
读完本文,你可以快速把握《智算中心是干什么的?建设目标、服务模式与企业应用场景解析》的关键问题与落地重点,并判断当前更值得优先推进哪些能力。
-
云算力是什么?GPU租赁、弹性调度与企业用算模式解析
读完本文,你可以快速理解《云算力是什么?GPU租赁、弹性调度与企业用算模式解析》涉及的核心概念、边界与适用场景,并判断它是否适合当前建设阶段。
-
Kubeflow部署难?Helm Chart一键安装Kubeflow实践
读完本文,你可以理解 Kubeflow 为什么常被认为难部署,以及 Helm Chart 在标准化安装和后续维护里到底能帮你省掉哪些坑。
-
大模型平台治理怎么做?从模型接入到权限审计的运营框架
读完本文,你可以梳理《大模型平台治理怎么做?从模型接入到权限审计的运营框架》的关键步骤与落地重点,并判断当前最该先补哪一层能力。
-
AI算力平台计费系统怎么设计?计量、计费与内部结算框架
读完本文,你可以快速把握《AI算力平台计费系统怎么设计?计量、计费与内部结算框架》的关键问题与落地重点,并判断当前更值得优先推进哪些能力。
-
人工智能算力平台怎么建?企业从资源纳管到统一服务的落地路径
读完本文,你可以梳理《人工智能算力平台怎么建?企业从资源纳管到统一服务的落地路径》的关键步骤与落地重点,并判断当前最该先补哪一层能力。
-
OpenFuyao技术介绍:企业AI基础设施开放能力与适用场景解析
读完本文,你可以快速把握《OpenFuyao技术介绍:企业AI基础设施开放能力与适用场景解析》的关键问题与落地重点,并判断当前更值得优先推进哪些能力。
-
Artificial General Intelligence:通用人工智能距离我们还有多远?
读完本文,你可以快速把握《Artificial General Intelligence:通用人工智能距离我们还有多远?》的关键问题与落地重点,并判断当前更值得优先推进哪些能力。
-
Conversational AI平台选型:企业级对话式AI解决方案对比
读完本文,你可以梳理《Conversational AI平台选型:企业级对话式AI解决方案对比》的关键步骤与落地重点,并判断当前最该先补哪一层能力。
-
AI Agent安全挑战:企业级智能体部署的三道防线
读完本文,你可以梳理《AI Agent安全挑战:企业级智能体部署的三道防线》的关键步骤与落地重点,并判断当前最该先补哪一层能力。
-
向量数据库怎么选?Milvus、Qdrant、Pinecone能力对比
读完本文,你可以建立《向量数据库怎么选?Milvus、Qdrant、Pinecone能力对比》的评估框架,并判断当前更该优先关注哪些能力、架构与取舍。
-
AI可观测性平台是什么?模型监控、漂移检测与告警体系
读完本文,你可以快速理解《AI可观测性平台是什么?模型监控、漂移检测与告警体系》涉及的核心概念、边界与适用场景,并判断它是否适合当前建设阶段。
-
AI平台ROI怎么评估?自建、采购与混合模式成本收益分析
读完本文,你可以拆清《AI平台ROI怎么评估?自建、采购与混合模式成本收益分析》涉及的投入、收益与隐性成本,并判断更适合当前阶段的测算口径。
-
大模型私有化部署多少钱?成本构成与投入测算方法
读完本文,你可以拆清《大模型私有化部署多少钱?成本构成与投入测算方法》涉及的投入、收益与隐性成本,并判断更适合当前阶段的测算口径。













AI平台与MLOps常见问题
MLOps主要解决什么问题?
MLOps 主要解决模型开发、训练、评估、部署和监控之间的断点问题。没有 MLOps 时,模型往往依赖人工记录实验、手工交付文件和临时脚本上线,版本追踪、回滚和质量评估都很困难。
落地时可以先从实验记录、模型版本、数据集版本和部署流程开始,不必一开始就建设完整平台。关键是让模型从研发到生产的每一步都可追踪、可复现、可审计。
AI平台和MLOps平台有什么区别?
AI平台范围更宽,通常包括算力、数据、开发环境、训练、推理、应用接入和权限治理;MLOps 更聚焦模型生命周期管理,包括实验、模型、部署、监控和迭代。MLOps 可以看作 AI 平台中的核心工程化能力。
如果团队正在从零开始建设,建议先明确主要业务是训练平台、推理平台还是模型治理平台,再决定功能边界。否则很容易做成大而全的门户,但关键流程仍然需要人工处理。
LLMOps和MLOps有什么不同?
LLMOps 继承了 MLOps 的模型生命周期思想,但更关注大模型应用中的 Prompt、RAG、知识库、工具调用、评估集、成本和安全风险。传统 MLOps 更偏向模型训练和模型版本,LLMOps 更偏向大模型应用运行和效果迭代。
企业落地大模型时,不能只关注模型是否能调用,还要关注回答质量、上下文管理、敏感数据、幻觉风险、调用成本和审计。LLMOps 的价值就在于把这些运行问题纳入工程化治理。
模型上线后为什么还需要持续监控?
模型上线后会遇到数据分布变化、性能波动、业务规则调整和用户输入变化。即使离线评估表现良好,线上也可能出现延迟升高、效果下降、异常输出或成本失控。
监控指标应同时覆盖工程指标和效果指标,例如延迟、吞吐、错误率、资源消耗、版本命中率、评估得分和人工反馈。只监控服务是否存活,无法判断模型是否仍然可用。