企业AI平台
企业AI平台标签聚合企业级 AI 平台、模型部署、算力调度、LLMOps、权限治理与生产级运维相关内容,适合关注 AI 平台建设和落地选型的读者。
-
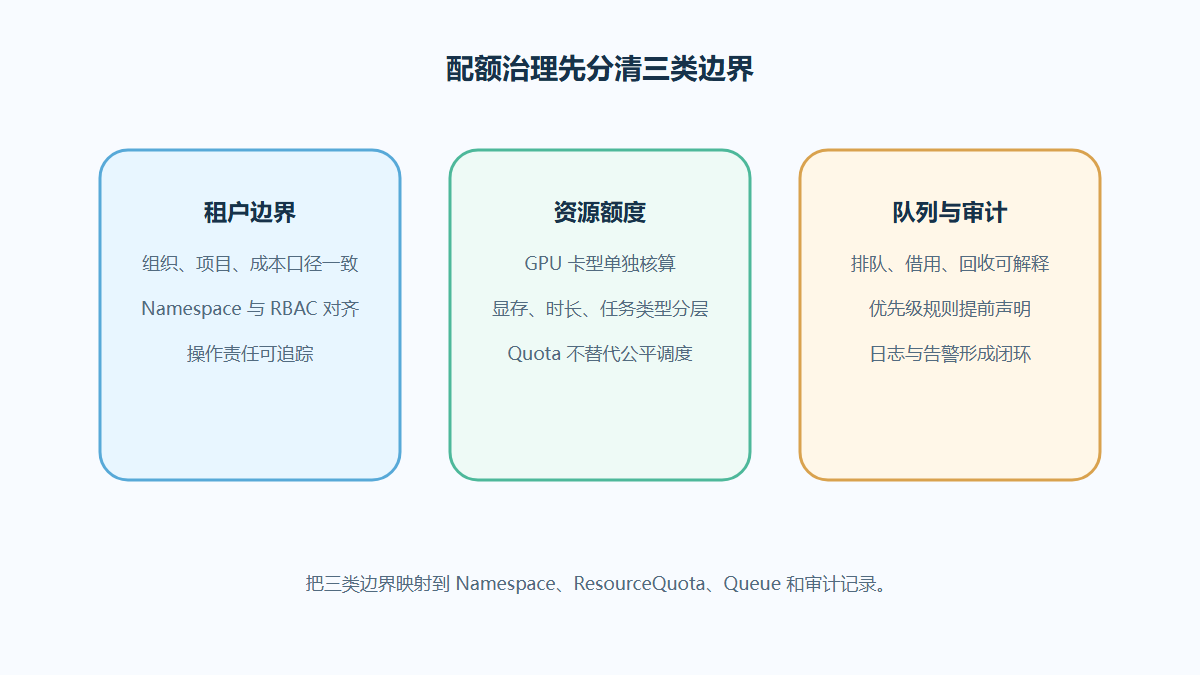
AI平台多租户配额怎么设计?设计租户和队列边界
当多个团队共用同一批 GPU 和模型环境时,AI平台多租户配额的难点常常不是资源本身,而是租户、队列、权限和借用规则没有说清。读完可获得一套可落地的治理检查路径。
-
GPU算力平台采购-5项POC验证点
GPU 资源紧张、团队抢卡和 AI 任务交付压力并存时,采购 POC 不能只跑通一个示例。本文围绕 GPU算力平台采购的 5 项验证点,拆解接入、调度、任务、观测和治理证据。
-
云原生AI基础设施架构-5层能力清单
AI应用从试点走向生产后,平台团队往往同时面对算力排队、模型追溯、推理发布和治理审计压力。本篇用5层能力清单拆解云原生AI基础设施,帮助你快速定位架构短板和下一步建设重点。
-
模型推理服务治理:路由、弹性与观测
模型上线后,真正难的是让不同版本、不同租户和不同负载稳定运行。本文从请求链路切入,拆解模型推理服务的路由、弹性、观测和风险控制,帮助平台团队建立上线后的治理视角。
-
GPU调度怎么做?队列配额落地路径
当训练任务排队、推理任务抢不到卡、团队之间争用算力时,问题通常不在单个 YAML。你可以从队列、配额、资源暴露和观测闭环四层理解 GPU调度,并形成可执行治理清单。
-
大模型部署到K8s怎么做?资源镜像服务上线要点
把大模型服务搬到 Kubernetes 后,最容易卡在镜像拉取慢、GPU 不可见、模型文件加载和服务暴露上。本篇按资源、镜像、模型和服务四条线梳理上线步骤与检查项。
-
企业AI平台建设:权限、算力与模型资产
模型、数据集、GPU 队列和推理服务分散在不同系统时,企业AI平台容易变成“能跑但难管”。本篇从项目权限、算力配额、模型版本和发布审计切入,帮助团队判断平台建设优先级。
-
企业AI平台运营看什么?资源利用率、SLA与成本指标
本文聚焦企业AI平台运营指标,从GPU利用率、任务等待、推理SLA、模型成本和团队分账解释平台如何持续优化。
-
AI平台多环境怎么设计?开发、训练、评估与生产隔离
本文聚焦AI平台多环境设计,从开发、训练、评估、灰度和生产推理解释资源、数据、权限和模型版本如何隔离治理。