本文定位:面向正在规划企业AI平台底座的平台、架构和运维团队,按能力分层评估云原生AI基础设施,不做厂商排名、价格比较或市场趋势判断。
云原生AI基础设施的难点,通常不在“有没有GPU”,而在算力、数据、模型、服务和治理能否被同一套平台能力稳定承接。试点阶段可以靠单集群、手工脚本和少量模型服务支撑;进入生产后,训练任务、推理服务、模型资产、成本归属和可观测闭环会同时出现,架构需要先把能力边界划清楚。
下面这份5层能力清单,适合用来做平台建设评审:先确认底座是否能承载AI工作负载,再看算力是否可调度、资产是否可追踪、服务是否可发布,最后检查治理闭环是否能支撑持续运行。
先看整体:云原生AI基础设施不是单点GPU集群
如果把云原生AI基础设施只理解成“在Kubernetes上挂GPU节点”,后续很容易出现三类问题:资源能分配但无法排队,模型能部署但灰度和回滚不可控,平台能跑任务但费用、权限和审计无法解释。
更合理的方式,是把它拆成5层能力:
- 资源与Kubernetes底座:负责集群、节点、命名空间、存储、网络和基础资源隔离。
- 异构算力与队列调度:负责GPU、CPU、内存、队列、配额、优先级和资源碎片治理。
- 数据、制品与模型资产:负责数据集、镜像、训练产物、模型版本和权限归属。
- 训练与推理服务:负责训练任务编排、模型服务发布、弹性伸缩、路由和灰度。
- 可观测与治理闭环:负责指标、日志、事件、成本、审计、策略和复盘。
Kubernetes 为容器化工作负载提供资源请求、限制和调度等基础机制,AI平台通常会在这个底座上扩展GPU设备插件、队列调度和任务编排能力[1]。NVIDIA device plugin 这类组件则把GPU资源以Kubernetes可识别的扩展资源形式暴露给工作负载[2]。


图1:云原生AI基础设施从资源底座到治理闭环的5层能力架构
这张分层图的价值,不是把所有组件堆在一起,而是帮助团队回答三个问题:当前缺的是基础资源、调度能力、模型服务,还是治理闭环?哪些能力必须平台统一建设?哪些能力可以先在业务团队局部试点?
第一层:资源与Kubernetes底座决定承载边界
资源底座是最容易被低估的一层。AI工作负载通常同时依赖GPU、CPU、内存、本地盘、对象存储、镜像仓库和高速网络,任何一个基础能力不稳定,都会放大到训练失败、推理抖动或成本失控。
上线前至少检查:
- 集群边界:训练、推理、开发测试是否共用集群,是否需要按环境、租户或安全级别拆分。
- 节点池规划:GPU节点、CPU节点、存储密集节点和通用节点是否分池管理。
- 资源隔离:命名空间、ResourceQuota、LimitRange、优先级和准入策略是否能约束误用。
- 基础存储:数据集、模型文件、缓存和日志分别使用什么存储路径,是否有容量和性能边界。
- 网络路径:训练数据读取、模型下载、推理访问和观测数据上报是否有清晰流向。
资源层的目标不是一次性做成“最大集群”,而是让平台知道什么资源可以被谁申请、以什么方式隔离、发生争用时按什么规则处理。如果这层没有做好,后面的调度器、模型服务和治理平台都会变成补丁式建设。
第二层:异构算力与队列调度负责把资源变成可用能力
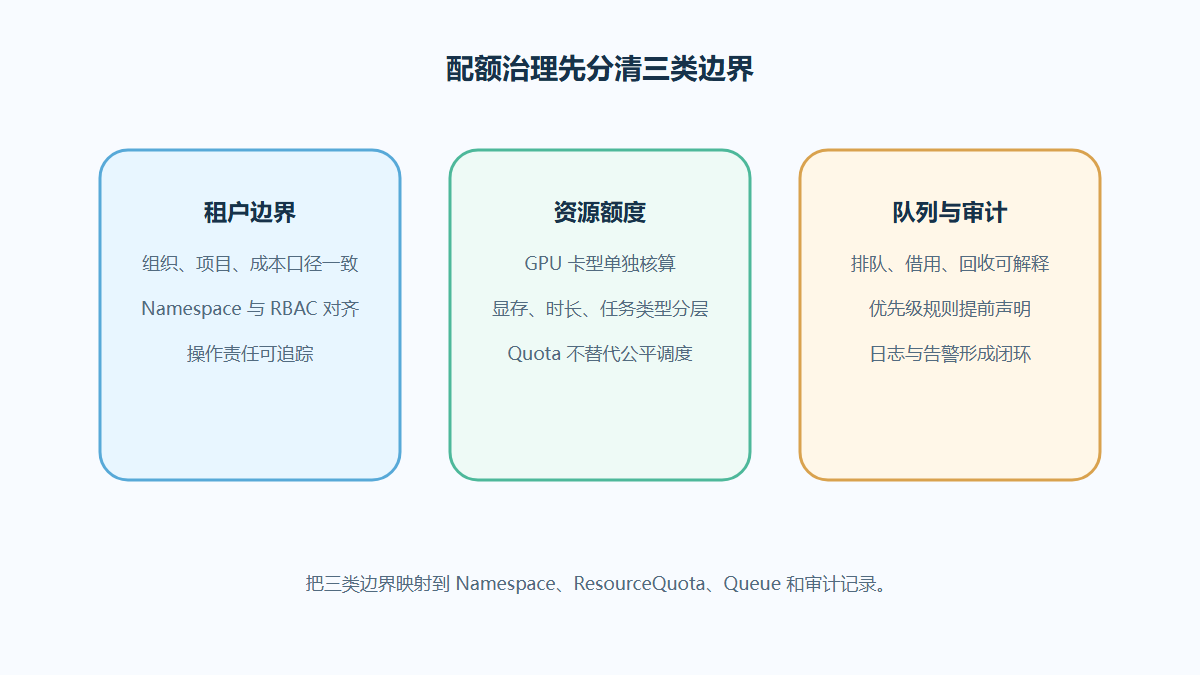
AI基础设施的核心矛盾往往是:硬件资源很贵,但任务需求波动大;训练任务希望长期占用,推理服务需要稳定低延迟,研发实验又需要快速获得资源。单纯按Pod调度,很难同时解决排队、公平性、优先级和资源碎片。
Kueue 这类Kubernetes原生队列系统强调以队列、资源配额和准入控制来管理批处理、训练等作业进入集群的时机[3]。在企业平台中,队列调度通常要回答以下问题:
| 能力项 | 需要回答的问题 | 常见风险 |
|---|---|---|
| 队列 | 哪些团队、项目或任务类型进入不同队列 | 队列过细导致资源碎片,过粗导致责任不清 |
| 配额 | GPU、CPU、内存和存储按什么口径分配 | 只设上限不设借用规则,资源利用率偏低 |
| 优先级 | 训练、推理、实验和紧急任务如何排序 | 高优任务长期挤占普通任务 |
| 抢占 | 资源不足时是否允许中断低优任务 | 没有检查点会造成训练进度损失 |
| 资源碎片 | 不同GPU型号、显存规格和拓扑如何匹配 | 任务能排队但无法找到合适节点 |
调度策略要跟业务承诺绑定
算力调度不能只看“集群利用率”,还要绑定业务承诺:哪些推理服务需要保底,哪些训练任务可以排队,哪些实验任务只能使用空闲资源。读者如果需要进一步理解队列、配额和GPU资源碎片治理,可以延伸阅读站内的 GPU调度 文章。
更稳妥的做法是把任务分成三类:
- 生产推理:优先保证稳定性和容量水位,避免被训练任务挤占。
- 关键训练:允许排队和配额借用,但需要检查点、失败重试和成本归属。
- 研发实验:优先使用共享资源或低优先级队列,避免影响生产任务。
第三层:数据、制品与模型资产连接训练和上线
很多AI平台建设失败,并不是模型跑不起来,而是训练产物、镜像版本、模型文件、评估结果和发布记录无法串起来。没有资产层,平台只能看到“某个任务成功了”,却很难回答“这个线上模型来自哪次训练、用了哪批数据、由谁批准发布”。
模型资产层通常要覆盖:
- 数据集登记:记录数据来源、权限、版本和适用范围。
- 镜像与依赖:把训练镜像、推理镜像和运行时依赖纳入制品管理。
- 训练产物:保留模型文件、指标、参数、日志和评估报告。
- 模型版本:区分实验版本、候选版本、灰度版本和线上版本。
- 审批与追溯:记录谁提交、谁评审、谁发布,以及回滚目标在哪里。
这层能力适合和企业已有的制品仓库、对象存储、权限系统和审计系统连接。不要把所有资产都做成一个“大模型仓库”概念,而要先明确每类对象的生命周期:数据能否复用、镜像是否可回滚、模型是否可追溯、评估结果是否能支撑上线判断。

图2:从数据集、训练任务到模型版本和推理发布的资产流转关系
图2建议把数据、镜像、训练产物和模型版本放在同一条资产链路里看。这样做可以避免一个常见误区:只关注训练框架或推理框架,却忽略模型进入生产前必须经过的版本、评估、审批和回滚路径。
第四层:训练与推理服务要分清批处理和在线服务
训练任务和推理服务都属于AI工作负载,但它们的运行特征不同:训练更像批处理,关注队列、资源占用、失败重试和检查点;推理更像在线服务,关注延迟、并发、弹性、灰度、路由和稳定性。
如果平台把两者都抽象成“跑一个容器”,短期会显得简单,长期会在上线治理中暴露问题:训练任务无法解释成本,推理服务无法做灰度,模型更新无法回滚,服务指标无法和模型版本对应。
训练与推理层可以按下面方式拆分:
| 工作负载 | 平台重点 | 典型检查项 |
|---|---|---|
| 训练任务 | 队列、资源申请、分布式任务、检查点、失败重试 | 任务是否可恢复,资源是否可归属,日志是否可追踪 |
| 批量推理 | 数据输入、批处理编排、吞吐、失败重跑 | 数据分片是否清晰,结果是否可校验 |
| 在线推理 | 服务发布、弹性伸缩、路由、灰度、限流 | 模型版本是否可回滚,延迟和错误率是否可观测 |
| 评估任务 | 指标计算、基准样本、报告归档 | 评估口径是否稳定,能否支撑上线决策 |
模型服务不是单纯部署Deployment
在线推理通常还需要流量治理、鉴权、灰度、配额和观测能力。关于模型服务层的路由、灰度、弹性和可观测治理,可以结合站内的 模型推理服务治理 继续阅读。
在架构评审时,建议把训练和推理的接口明确区分:训练产出候选模型,评估任务给出是否上线的依据,推理服务承接线上流量,治理层持续反馈模型服务的运行状态。
第五层:可观测与治理闭环让平台能持续运行
云原生AI基础设施进入生产后,最怕的是“能跑但不可解释”。当模型服务变慢、GPU利用率异常、队列等待过长或某个团队费用突增时,平台必须能从指标、日志、事件、模型版本和资源归属中追溯原因。
治理闭环至少包含四类信号:
- 资源信号:GPU利用率、显存、CPU、内存、网络和存储吞吐。
- 任务信号:排队时长、运行时长、失败原因、重试次数和检查点状态。
- 服务信号:请求量、延迟、错误率、限流、灰度和模型版本。
- 治理信号:租户、项目、成本、审批、审计和策略命中记录。

图3:从运行信号、策略判断到复盘改进的AI基础设施治理闭环
治理闭环的重点不是把所有数据都采集进来,而是让关键问题能被定位:等待是因为配额不足、资源碎片还是优先级设置不合理?推理抖动是因为模型版本、流量突增还是节点资源竞争?费用上涨是因为训练重跑、推理扩容还是资源长期空闲?
架构落地路线:先补共同底座,再做高级治理
云原生AI基础设施不适合一次性按“大平台”推进。更稳妥的落地路径,是先找出所有团队都会复用的共同底座,再逐步补齐调度、资产、服务和治理能力。
建议按三步推进:
- 建立统一资源口径:先明确集群、节点池、GPU资源、命名空间、配额和成本归属,避免不同团队各自建设孤岛。
- 打通任务到资产链路:把训练任务、镜像、模型文件、评估结果和发布记录关联起来,形成可追溯路径。
- 形成服务治理闭环:把推理服务的流量、版本、弹性、可观测和回滚纳入平台能力,而不是依赖人工变更。
不同阶段的建设重点不同
| 阶段 | 建设重点 | 不建议过早投入 |
|---|---|---|
| 试点期 | GPU节点池、基础镜像、训练任务模板、模型文件归档 | 复杂多租户计费、全自动模型发布 |
| 扩展期 | 队列调度、配额、模型版本、推理服务治理 | 过细的组织级流程、过度定制调度策略 |
| 生产期 | 审计、成本、灰度、回滚、容量规划和复盘机制 | 只追求资源利用率而忽略服务稳定性 |
落地路线要服务平台阶段
这条路线可以降低平台建设风险:先让资源和资产可管理,再让训练和推理可发布,最后用治理闭环支撑长期演进。
小结
云原生AI基础设施的价值,不是把GPU、Kubernetes、模型仓库和推理框架简单组合,而是把它们组织成可复用、可追溯、可治理的企业AI平台底座。5层能力清单可以作为架构评审框架:资源底座决定承载边界,异构算力调度决定资源效率,数据与模型资产决定可追溯性,训练与推理服务决定上线能力,可观测与治理闭环决定长期稳定运行。
如果团队正在从AI试点走向生产,建议先用这5层检查现状:哪些能力已经平台化,哪些仍靠人工脚本,哪些缺少明确责任边界。只要这些问题被拆清楚,后续再选择调度器、模型服务框架或治理平台时,就不会只围绕单个工具做决策。
参考资料
- [1] Kubernetes Resource Management for Pods and Containers
- [2] NVIDIA Kubernetes Device Plugin
- [3] Kueue Overview
常见问题
云原生AI基础设施和普通Kubernetes平台有什么区别?
普通Kubernetes平台主要解决容器化应用的部署、调度、网络、存储和运维问题。云原生AI基础设施在此基础上进一步引入GPU等异构资源、队列调度、训练任务、模型资产、推理服务和治理闭环。它不只是“更大的集群”,而是要把AI工作负载从实验、训练、评估到上线的链路纳入平台管理。
企业AI平台底座应该先建设哪一层?
通常建议先从资源与Kubernetes底座开始,明确节点池、命名空间、配额、存储和网络边界;随后补齐异构算力与队列调度,避免GPU资源被零散占用。数据、模型资产和推理治理可以并行试点,但不要在资源口径还不清晰时先做复杂门户,否则容易变成只有界面、缺少平台约束的入口系统。
云原生AI基础设施一定需要队列调度系统吗?
不一定。小规模试点可以先用基础调度和人工配额管理,但只要出现多团队共享GPU、训练任务排队、资源借用、优先级或抢占诉求,就需要引入更明确的队列调度能力。是否上队列系统,应取决于任务规模、资源争用程度、成本归属和生产推理稳定性要求,而不是单纯看集群节点数量。
模型资产管理和制品仓库可以共用吗?
可以复用底层制品仓库或对象存储,但模型资产需要额外记录版本、评估结果、训练参数、审批状态和发布关系。只保存模型文件并不等于完成模型资产管理;真正关键的是能回答“这个线上模型从哪里来、用什么数据训练、评估是否通过、失败时回滚到哪个版本”。
可观测能力应该从训练任务还是推理服务开始?
如果已有线上推理服务,建议先从推理服务开始,因为延迟、错误率、版本和流量变化直接影响用户体验。如果仍处于训练平台建设阶段,可以先从队列等待时长、任务失败原因、GPU利用率和检查点状态入手。两者最终应汇总到同一治理视角,支持容量规划、成本复盘和稳定性改进。
<!– image_requirements: required_image_count: 3 images: – path: ../images/2026-05-25-seo-batch/ai-infra-arch-01.svg alt: 云原生AI基础设施5层能力架构 caption: 图1:云原生AI基础设施从资源底座到治理闭环的5层能力架构 section: 先看整体:云原生AI基础设施不是单点GPU集群 image_type: 整体架构图 reader_task: 快速理解资源底座、算力调度、模型资产、训练推理和治理闭环之间的分层关系 key_terms: 云原生AI基础设施,Kubernetes底座,异构算力,模型资产,推理服务,治理闭环 – path: ../images/2026-05-25-seo-batch/ai-infra-arch-02.svg alt: AI平台数据制品与模型资产流转 caption: 图2:从数据集、训练任务到模型版本和推理发布的资产流转关系 section: 第三层:数据、制品与模型资产连接训练和上线 image_type: 数据流图 reader_task: 看清数据集、镜像、训练产物、模型版本、评估和发布之间的追溯链路 key_terms: 数据集,训练任务,镜像制品,模型版本,评估报告,推理发布 – path: ../images/2026-05-25-seo-batch/ai-infra-arch-03.svg alt: 云原生AI基础设施治理闭环 caption: 图3:从运行信号、策略判断到复盘改进的AI基础设施治理闭环 section: 第五层:可观测与治理闭环让平台能持续运行 image_type: 闭环链路图 reader_task: 理解资源信号、任务信号、服务信号和治理动作如何形成持续改进闭环 key_terms: 可观测,指标,日志,队列等待,模型版本,成本归属,审计,复盘 –>