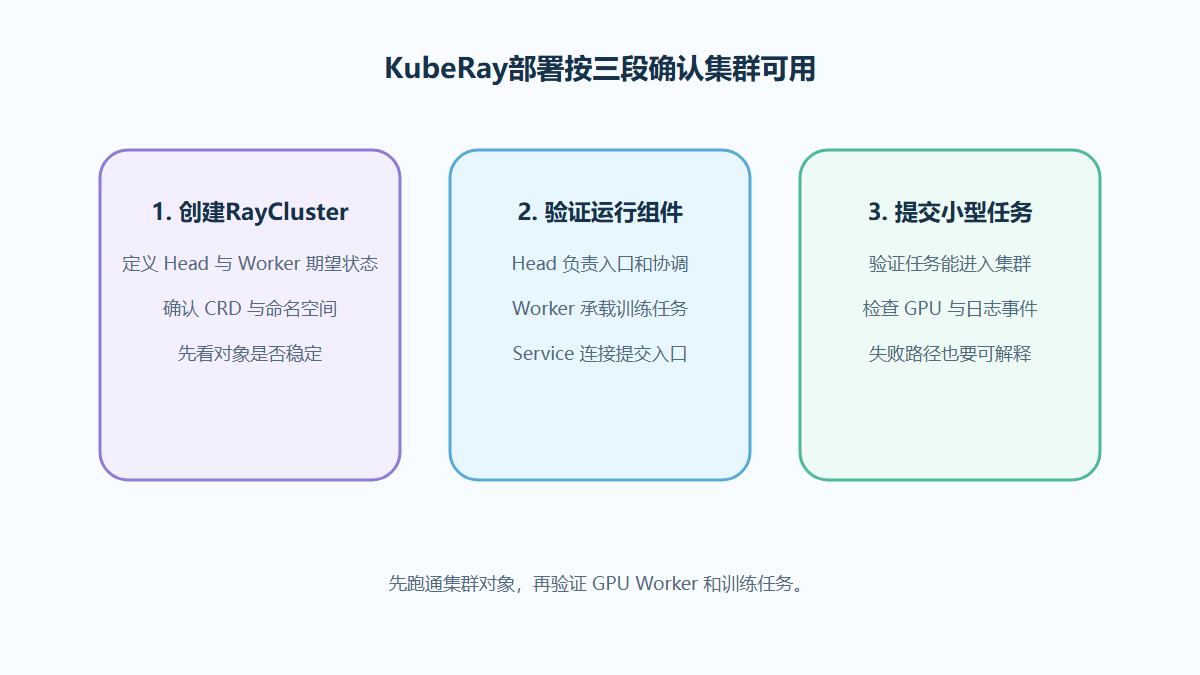
本文定位:面向正在做 K8s模型推理扩缩容的团队,重点讨论扩缩容决策链路;不提供性能承诺,也不假设某一种指标适合所有模型和流量。
K8s模型推理扩缩容的难点在于,推理服务不像普通 Web 服务那样只看 CPU 或请求数。GPU 显存、模型加载时间、队列长度、并发上限和实例就绪状态都会影响弹性效果。要减少误判,需要先把请求链路画清楚。
K8s模型推理扩缩容先看请求链路
一个推理请求进入平台后,可能经过网关、路由、队列、推理实例和模型运行时。扩容动作发生得太晚,用户会感知排队;缩容动作过于激进,下一波请求又会遭遇冷启动。
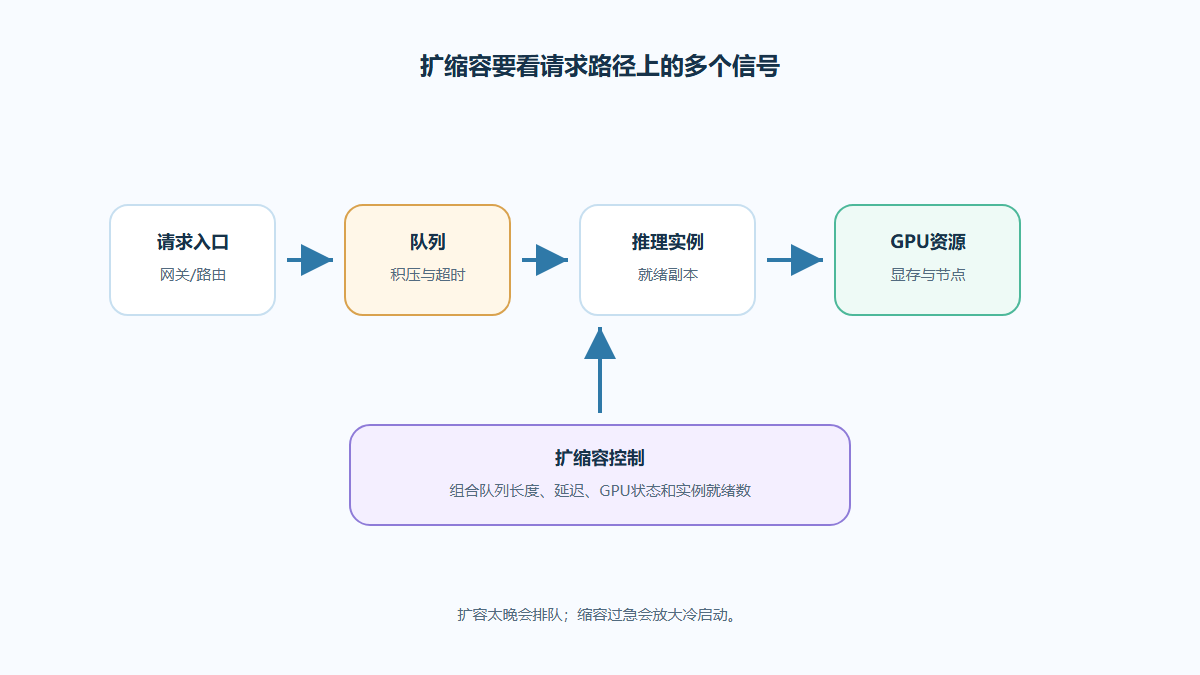

图1:推理扩缩容请求链路图要同时观察请求、队列、GPU资源和实
在 模型推理 场景中,扩缩容目标通常不是“副本越多越好”,而是在资源成本、响应体验和稳定性之间找到可接受区间。
HPA能解决什么,不能解决什么
HPA 适合根据可观测指标调整副本数,但它不能自动理解模型加载时间、显存碎片、队列策略或业务优先级。如果指标选错,HPA 可能会看起来工作正常,却没有解决真实瓶颈。
| 指标类型 | 能反映什么 | 局限 |
|---|---|---|
| CPU / 内存 | 通用资源压力 | 可能不能代表 GPU 推理瓶颈 |
| GPU 使用率 | 设备繁忙程度 | 需要结合显存和请求排队看 |
| 队列长度 | 请求积压情况 | 过短窗口可能放大抖动 |
| 请求延迟 | 用户体验变化 | 可能滞后于资源压力 |
| 实例就绪数 | 可接流量副本 | 无法单独说明扩容原因 |
指标要服务扩缩容动作
如果指标只能描述“已经慢了”,扩容就会滞后;如果指标过于敏感,副本会频繁抖动。推理扩缩容更适合组合指标判断,例如队列长度 + GPU 显存 + 就绪实例,而不是只看单个平均值。
队列、并发和GPU显存怎么共同影响扩缩容
队列可以吸收短时流量峰值,但队列过长会把延迟问题隐藏起来。并发可以提高单实例吞吐,但过高并发可能压满显存或让请求等待时间变长。GPU 显存则决定一个实例能承载多少模型和上下文。

图2:只看 CPU 不足以判断 GPU 推理服务是否需要扩容
建议把扩缩容拆成三类判断:
- 是否需要扩容:请求是否持续排队,延迟是否超过目标区间。
- 能否扩容成功:节点是否有 GPU、显存和配额,调度是否允许。
- 扩容是否值得:新实例加载模型的时间是否短于流量峰值持续时间。
这里会自然连接到 算力调度:如果 GPU 节点、队列和配额没有准备好,HPA 发出扩容意图也可能无法获得资源。
冷启动为什么会拖慢推理体验
推理服务冷启动通常不只是容器启动。镜像拉取、模型文件加载、运行时初始化、显存分配和探针就绪都会增加时间。对于大模型服务,扩容副本到可接流量之间可能存在明显延迟。
| 冷启动阶段 | 可能影响 | 优化方向 |
|---|---|---|
| 镜像准备 | Pod 创建变慢 | 镜像预拉取、节点缓存 |
| 模型加载 | 就绪时间变长 | 模型缓存、分层存储、预热 |
| 显存分配 | 启动失败或延迟 | 控制并发、预估显存预算 |
| 探针就绪 | 流量进入时机不准 | 区分启动、存活和就绪探针 |
预热比事后扩容更适合部分场景
如果业务峰值可预测,可以考虑保留最小副本、定时预热或提前扩容;如果流量不可预测,则要接受一部分冷启动成本,并用队列和超时策略保护用户体验。
企业平台如何设置推理扩缩容边界
平台团队不应只给用户一个“自动扩缩容开关”。更成熟的做法是提供默认策略、可调参数和风险提示,让不同模型按场景选择弹性方式。
落地时可以先定义:
- 最小副本和最大副本范围。
- 扩容指标组合和采样窗口。
- 队列长度、超时和拒绝策略。
- GPU 节点池、配额和优先级。
- 模型加载、探针和回滚条件。

图3:扩容速度、显存占用和冷启动时间需要一起权衡
小结
K8s 模型推理扩缩容不能只依赖 HPA,也不能只看 GPU 利用率。请求链路、队列、显存、冷启动和资源配额共同决定弹性效果。
更稳妥的策略是:先定义用户体验目标,再选择指标组合,最后确认资源和冷启动边界。对于企业平台,还要把扩缩容策略纳入租户配额、队列优先级和观测告警中统一治理。
常见问题
1. K8s模型推理扩缩容可以只用HPA吗?
可以从 HPA 开始,但不建议只看 CPU 或内存。推理服务还需要结合 GPU、队列、延迟和就绪状态判断,否则可能出现指标正常但请求体验不稳定的情况。
2. GPU利用率低是不是应该缩容?
不一定。GPU 利用率低可能来自流量低、请求等待、模型加载、batch 策略或观测口径问题。缩容前要确认延迟、队列和最小副本要求,避免下一波请求被冷启动拖慢。
3. 推理服务冷启动能完全消除吗?
通常只能降低影响,很难在所有场景完全消除。可以通过预热、模型缓存、最小副本和探针策略缩短感知时间,但这些动作会增加资源占用,需要按业务峰值和成本边界权衡。
4. 队列长度适合作为扩容指标吗?
适合,但要配合采样窗口、延迟和资源可用性一起看。队列长度太敏感会导致抖动,太迟钝又会让扩容滞后。建议用真实流量回放或灰度环境先验证阈值。